Flink架构及部署
概述
Apache Flink是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态计算。Flink被设计成可以在所有常见的集群环境中运行。
- 有界流:有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理
- 无界流:有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
架构
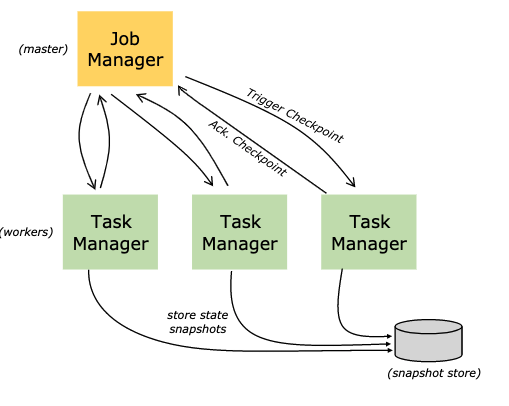
Flink由一个JobManager和一个或多个TaskManager组成。
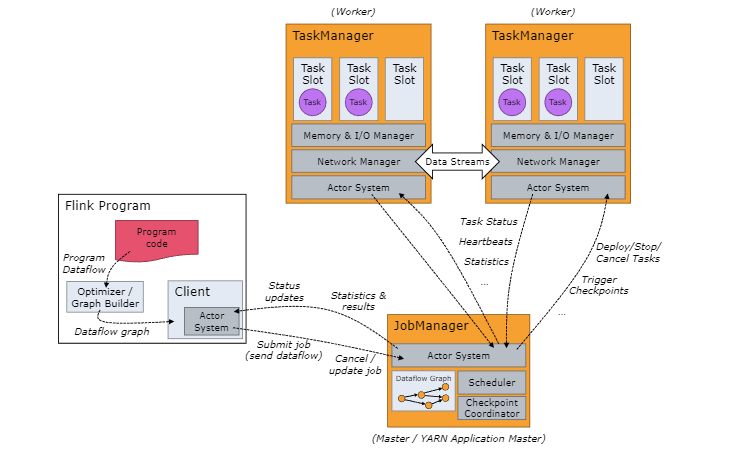
JobManager
ResourceManager
ResourceManager 负责 Flink 集群中的资源提供、回收、分配 - 它管理 task slots,这是 Flink 集群中资源调度的单位(请参考TaskManagers)。Flink 为不同的环境和资源提供者(例如 YARN、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。在 standalone 设置中,ResourceManager 只能分配可用 TaskManager 的 slots,而不能自行启动新的 TaskManager。
Dispatcher
Dispatcher 提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。
JobMaster
JobMaster 负责管理单个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。
TaskManager(也称为 worker)执行作业流的 task,并且缓存和交换数据流。在 TaskManager 中资源调度的最小单位是 task slot。TaskManager 中 task slot 的数量表示并发处理 task 的数量。请注意一个 task slot 中可以执行多个算子。算子包括source、transformation、sink。数据来源、数据聚合转换、数据结果输出每个过程都可以认为是一个算子。
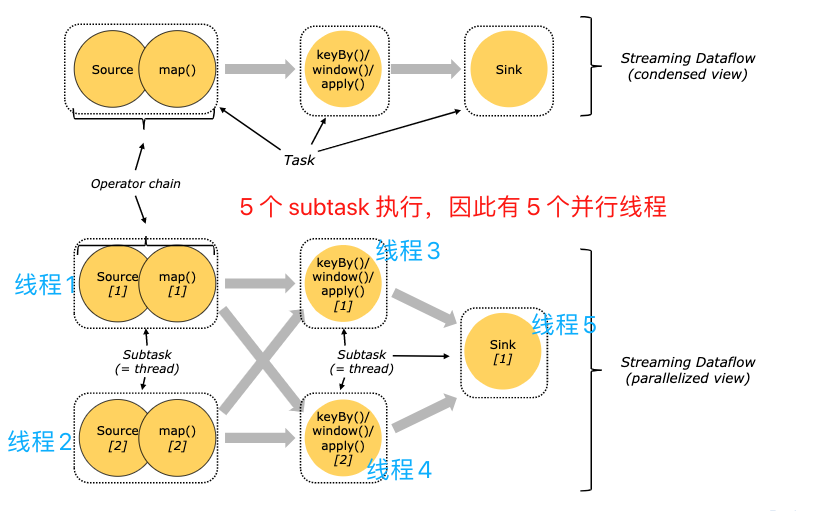
对于分布式执行,Flink 将算子的 subtasks 链接成 tasks,每个 task 由一个线程执行,中source和map算子组成一个算子链,作为一个task运行在一个线程上,将算子链接成 task 是个有用的优化:它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量。
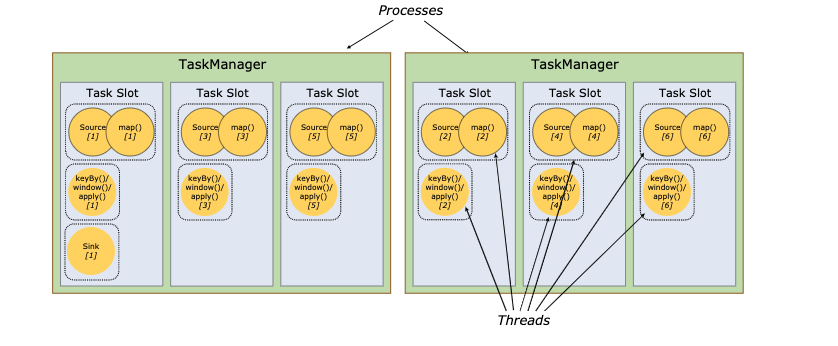
Task Slots 任务槽,每个worker(TaskManager)是一个JVM 进程,可以有一个或多Solt,Task Slot是Flink中的任务执行器,每个Task Slot可以运行多个subtask ,所有Task Slot平均分配TaskManger的内存, TaskSolt 没有 CPU 隔离每个subtask会以单独的线程来运行,task solt数量建议是cpu的核数,独占内存,共享CPU。