Redis面试题
BigKey、HotKey问题如何预防和解决
会导致的问题:会使服务的性能下降 ,还会影响用户正常使用功能,甚至会造成大范围的服务故障,发生系统雪崩。
在Redis中,一个字符串类型最大可以到512MB,一个二级数据结构(比如hash、list、set、Zset等)可以存储大约40亿个(2^32-1)个元素,但实际上不会达到这么大的值,一般情况下如果达到下面的情况,就可以认为它是Bigkey了。
- 单个string类型的value值超过1MB,就可以认为是Bigkey。
- 哈希、列表、集合、有序集合等,它们的元素个数超过2000个,就可以认为是Bigkey。
HotKey: 一个key对应在一个redis分片中,当短时间内大量的请求打到该分片上,key被频繁访问,该key就是热key。
bigKey的问题:
- 数据请求大量超时,redis读取数据是单线程的,当一个key数据响应的久一点,就会造成后续请求频繁超时。
- 侵占带宽,当一个key所占空间过大,多次请求就会占用比较大的带宽,直接影响服务的正常运行。
- 内存溢出活处理阻塞:当一个较大的key存在时,持续新增,key所占内存会越来越大,严重时会导致内存数据溢出;当key过
期需要删除时,由于数据量过大,可能发生主库较响应时间过长,主从数据同步异常(删除掉的数据,从库还在使用)。 - 迁移困难:对key进行迁移时,是通过 migrate 命令来完成的,migrate 实际上是通过 dump + restore + del 三个命令组合成原子命令完成,它在执行的时候会阻塞进行迁移的两个实例,直到以下任意结果发生才 会释放:迁移成功,迁移失败,等待超时
hotkey的问题:
- 分片服务瘫痪:redis集群会分很多个分片,每个分片有其要处理的数据范围。当某一个分片被频繁请求,该分片服务就 可能会瘫痪。
- redis分布式集群优势弱化:请求不够均衡,过于单点,那么redis分布式集群的优势也必然被弱化
- 可能造成资产损失
- 引发缓存击穿:当缓存请求不到,就会去请求数据库。如果请求过于集中,redis承载不了,就会有大量请 求打到数据库。此时,可能引发数据库服务瘫痪。进而引发系统雪崩
- cpu占用高,影响其他服务:单个分片cpu占用率过高,其他分片无法拥有cpu资源,从而被影响
如何发现bigkeys和hotkeys
使用自带命令
##查看bigkey redis-cli -a 登录密码 --bigkeys ##查看hotkey redis-cli -a 登录密码 --hotkeys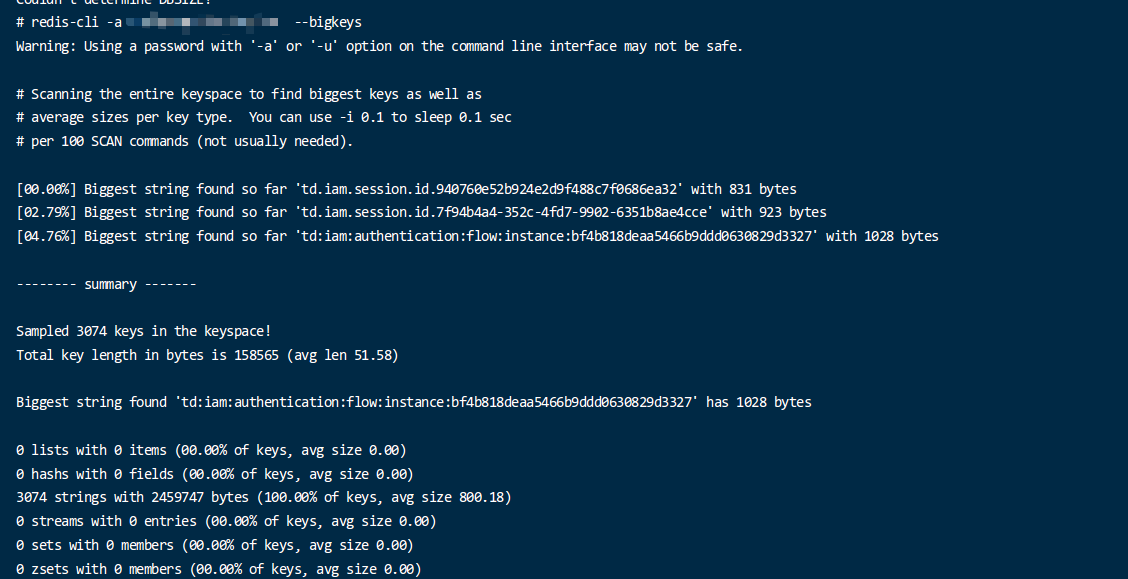
scan扫描+长度命令
redis-rdb-tools开源工具
GitHub地址:https://github.com/sripathikrishnan/redis-rdb-tools
解决方案
bigkey:
- 对bigkey进行拆分
- 对bigkey进行清理,使用unlink命令进行删除
- 定期清理失效数据
hotkey:
增加redis集群副本数量,将hotkey尽量分散到不同节点,但是存在极端情况下hotkey还是分布在同一个节点上。
使用二级缓存(本地缓存)
使用本地缓存需要注意两个问题:
- 如果对热
Key进行本地缓存,需要防止本地缓存过大,影响系统性能; - 需要处理本地缓存和
Redis集群数据的一致性问题。
- 如果对热
热key备份,将热key备份并分布到不同节点,但是要注意备份的一致性问题。通过一个大于等于
1小于M的随机数,得到一个bakHotKey,程序会优先访问bakHotKey,在得不到数据的情况下,再访问原来的hotkey,并将hotkey的内容写回bakHotKey。值得注意的是,bakHotKey的过期时间是hotkey的过期时间加上一个较小的随机正整数,这是通过坡度过期的方式,保证在hotkey过期时,所有bakHotKey不会同时过期而造成缓存雪崩。
亿级用户日活统计有几种方案
- 利用 bitmap 实现
- 利用 HyperLogLog 实现
hyperloglog只会根据元素来计算基数,不会存储元素本身,所以不能像其它类型一样返回各个元素 hyperloglog是概率算法,是牺牲准确率换区空间的, 对于对精度要求不高的情况下可以使用,因为概率算法本身不直接存储数据本身,能保证误差在一定范 围内,又不占用空间,误差在0.81%左右
在 Redis 中实现的 HyperLogLog,只需要12K内存就能统计2^64 个数据。不过有得必有失,HyperLogLog计数存在一定的误差,误差率整体较低。标准误差为 0.81% ,不到1%。当然,误差可以被设置辅助计算因子进行降低。
HLL算法的优点在于它具有极低的内存消耗和高效的计算速度,并且可以处理极大的数据集。
HyperLogLog与bitmap对比
1、bitmap 优势是:非常均衡的特性,精准统计,可以得到每个统计对象的状态,秒出。 缺点是:当你的统计对象数量十分十分巨大时,可能会占用到一点存储空间,但也可在接受范围内。也可以通过分片,或者压缩的额外手段去解决。
注意:bitmap是精确的
2、HyperLogLog 优势是: 可以统计夸张到无法想象的数量,并且占用小的夸张的内存。 缺点是: 建立在牺牲准确率的基础上,而且无法得到每个统计对象的状态。
生产环境上Redis设置的内存是多少,如何修改redis内存?
如果不设置内存大小,在64位操作系统下不限制内存大小,在32位操作系统下最多使用3G。使用info memory查看内存使用情况。
> info memory
- used_memory:由 Redis 分配器分配的内存总量,包含了redis进程内部的开销和数据占用的内存,以字节(byte)为单位
- used_memory_human:已更直观的单位展示分配的内存总量。
- used_memory_rss:向操作系统申请的内存大小。与 top 、 ps等命令的输出一致。
- used_memory_rss_human:已更直观的单位展示向操作系统申请的内存大小。
- used_memory_peak:redis的内存消耗峰值(以字节为单位)
- used_memory_peak_human:以更直观的格式返回redis的内存消耗峰值
- used_memory_peak_perc:使用内存达到峰值内存的百分比,即(used_memory/used_memory_peak) *100%
- used_memory_overhead:Redis为了维护数据集的内部机制所需的内存开销,包括所有客户端输出缓冲区、查询缓冲区、AOF重写缓冲区和主从复制的backlog。
- used_memory_startup:Redis服务器启动时消耗的内存
- used_memory_dataset:数据占用的内存大小,即used_memory-sed_memory_overhead
- used_memory_dataset_perc:数据占用的内存大小的百分比,100%*(used_memory_dataset/(used_memory-used_memory_startup))
- total_system_memory:整个系统内存
- total_system_memory_human:以更直观的格式显示整个系统内存
- used_memory_lua:Lua脚本存储占用的内存
- used_memory_lua_human:以更直观的格式显示Lua脚本存储占用的内存
- maxmemory:Redis实例的最大内存配置
- maxmemory_human:以更直观的格式显示Redis实例的最大内存配置
- maxmemory_policy:当达到maxmemory时的淘汰策略
- mem_fragmentation_ratio:碎片率,used_memory_rss/ used_memory
- mem_allocator:内存分配器
- active_defrag_running:表示没有活动的defrag任务正在运行,1表示有活动的defrag任务正在运行(defrag:表示内存碎片整理)
- lazyfree_pending_objects:0表示不存在延迟释放的挂起对象
可以通过修改配置文件和命令两种方式修改内存。
配置文件修改:

命令修改:
> config set maxmemory 104857600
"OK"
> config get maxmemory
1) "maxmemory"
2) "104857600"
注意
一般推荐Redis设置内存为最大物理内存的四分之三,也就是0.75
Redis内存淘汰策略
内存淘汰策略:
- noeviction: 不会驱逐任何key(6.x默认是这个)
- allkeys-lru: 对所有key使用LRU算法进行删除
- volatile-lru: 对所有设置了过期时间的key使用LRU算法进行删除
- allkeys-random: 对所有key随机删除
- volatile-random: 对所有设置了过期时间的key随机删除
- volatile-ttl: 删除马上要过期的key
- allkeys-lfu: 对所有key使用LFU算法进行删除
- volatile-lfu: 对所有设置了过期时间的key使用LFU算法进行删除
一般使用 allkeys-lru。