ClickHouse介绍
概述
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
- 什么是OLTP
- 全称 OnLine Transaction Processing,联机事务处理系统, 就是对数据的增删改查等操作
- 存储的是业务数据,来记录某类业务事件的发生,比如下单、支付、注册、等等
- 典型代表有Mysql、 Oracle等数据库,对应的网站、系统应用后端数据库
- 针对事务进行操作,对响应时间要求高,面向前台应用的,应用比较简单,数据量相对较少,是GB级别的
- 行式存储
- 面向群体:业务人员
- 什么是OLAP
- OnLine Analytical Processing,联机分析处理系统
- 存储的是历史数据,对应的风控平台、BI平台、数据可视化等系统就属于
- OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策,并且提供直观易懂的查询结果
- 典型代表有 Hive、ClickHouse
- 针对基于查询的分析系统,基础数据来源于生产系统中的操作数据,数据量非常大,常规是TB级别的
- 列示存储
- 面向群体:分析决策人员
行式存储与列示存储区别
行式存储:一行中的数据在存储介质中以连续存储形式存在。
列示存储:在底层的存储介质上,数据是以列的方式来组织的,存储完若干条记录的首个字段后,再存储这些记录的第二个字段,然后再第三个字段、第四个字段...
特性
列存储
不是将每一行中的所有值存储在一起,而是将每一列中的值存储在一起,此时查询分析就只需要读取和解析需要的列,从而节省大量工作。如下图所示:
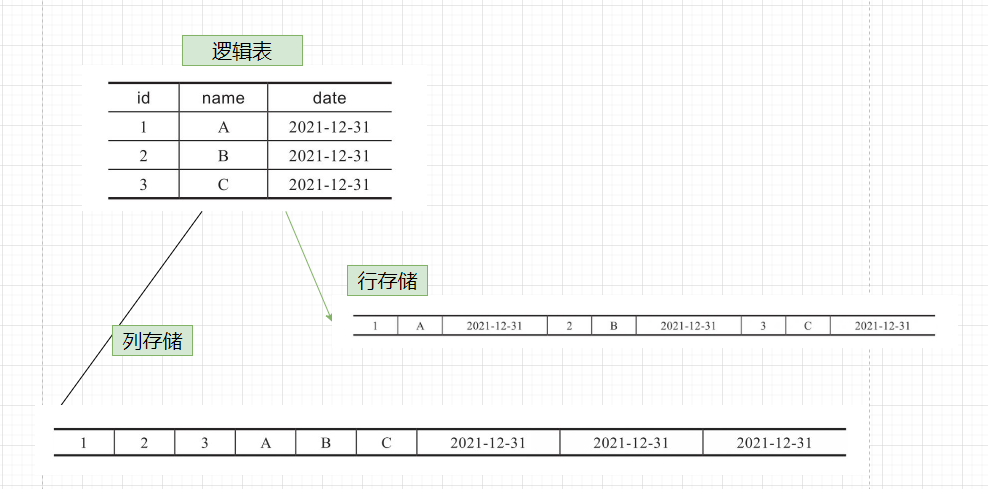
使用列存储在OLAP中有很多优势,一般统计分析通常是在某个字段上进行操作,列存储可以大大减少数据扫描I/O。另外,相同列的数据类型通常相同,可以获得更优的压缩率,大大减少数据存储。针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中可以只读取需要的数据列。
向量化查询执行引擎
"向量化查询执行引擎"通常指的是在数据库或数据处理系统中采用向量化计算的方法来执行查询操作。这一方法的目的是通过利用现代硬件的向量处理单元,如SIMD(Single Instruction, Multiple Data)指令集,来加速查询和分析任务。
在传统的查询执行中,通常是对数据集中的每个元素逐个进行操作,这在处理大规模数据时可能效率较低。相比之下,向量化查询执行引擎通过同时处理多个数据元素,以矢量化的方式执行查询操作,从而提高了计算效率。这种方法特别适用于处理大规模的数据集,例如数据仓库或分析型数据库中的查询操作。
数据压缩
数据体积的减小可以非常有效地减少磁盘空间占用,提高I/O性能,这对整体查询性能的提升非常有效。通常情况下,查询消耗在I/O方面的时间远大于消耗在数据解压缩方面的时间。除了使用通用的压缩编解码器,ClickHouse还针对特定类型的数据设计了专用的编解码器,实现了更加优异的性能。官方数据显示,通过使用列存储,在某些分析场景下,加速效果可以提升100倍甚至更高。这背后的重要原理有如下几点。
支持SQL
ClickHouse支持基于SQL的声明式查询语言,支持GROUP BY、ORDER BY、FROM、JOIN、IN以及其他非相关子查询。
稀疏索引
ClickHouse支持主键索引。它根据索引粒度(默认为8192行)对每一列数据进行划分。每个索引粒度开头的第一行称为标记行。主键索引存储了标记行对应的主键的值。对于WHERE条件下有主键的查询,主键索引的二分查找可以直接定位到对应的索引粒度,避免了全表扫描,加快了查询速度。
运行时代码生成
经典的数据库实现通常使用火山模型进行表达式计算,即将查询转化为一个算子,如hashjoin、scan、indexscan、aggregation等。为了连接不同的算子,算子采用统一的API,如open()、next()、close()函数等。在分析场景中一条SQL语句通常需要处理数亿行数据,此时虚函数的调用成本很高。另外,每个算子都要考虑多种变量,如列类型、列大小、列数等,if-else分支判断的数量较多,进而导致CPU分支预测失败。
ClickHouse实现了在运行时根据当前SQL动态生成代码,然后编译执行。这样不仅消除了大量的虚函数调用,而且消除了由于参数类型造成的不必要的if-else分支判断性能损耗。
支持近似计算
ClickHouse支持数据采样,支持在允许牺牲数据精度的情况下对查询进行加速。在海量数据处理中,近似计算带来的性能体验的提升特别明显。
数据TTL
在分析场景中,数据的价值随着时间的推移而降低。大多数企业只是出于成本考虑保留最近几个月的数据。ClickHouse通过TTL提供数据生命周期管理的能力。ClickHouse支持几种不同粒度的TTL。
- 列级TTL:当列中的部分数据过期时,将这些数据替换为默认值;当该列中的所有数据都已过期时,该列将被删除。
- 行级TTL:当一行的所有数据过期时,直接删除该行。
- 分区级别TTL:当一个分区过期时,该分区将被直接删除。
多核心并行计算
ClickHouse会使用服务器上一切可用的资源并行处理大型查询任务。当然,这也导致ClickHouse有一个致命缺点,就是QPS瓶颈。如果集群中遇到一个超大数据量的查询计算,会把集群CPU、内存资源耗尽,而此时其他查询只能等待。
多服务器分布式计算
ClickHouse支持分布式查询。在ClickHouse中,数据可以保存在不同的分片(Shard)上,每一个分片都由一组用于容错的副本(Replica)组成,查询可以并行地在所有分片上进行处理。
分片和副本
ClickHouse支持单机模式和分布式集群模式。在分布式模式下,ClickHouse会将数据分成多块,并分发到不同的节点。不同的分片策略在处理不同的SQL模式时各有优势。
在多个副本的情况下,ClickHouse提供了多种查询分发策略,列举如下。
随机分布:从多个副本中随机选择一个。
最新主机名原则:选择与当前分布的机器最相似的主机名节点并发出查询。在特定的网络拓扑中,这种策略可以减少网络延迟,而且可以保证查询分布到固定的副本机器上,充分利用系统缓存。❑按顺序:尽量按照特定的顺序一一分发。当前副本不可用时,将推迟到下一个副本。
第一个或者随机:在顺序模式下,当第一个副本不可用时,所有的工作负载都会积压到第二个副本,导致负载不平衡。“第一个或随机策略”解决了这个问题:当第一个副本不可用时,随机选择另一个副本,确保剩余副本之间的负载平衡。另外,在跨地域复制场景下,将第一个副本设置为地域内的副本,可以显著降低网络延迟。