ClickHouse安装及基本使用
部署
Docker部署
## 创建挂载目录并授权
mkdir -p /data/clickhouse && chmod -R 777 /data/clickhouse
## 启动
docker run -d --name clickhouse --ulimit nofile=262144:262144 \
-p 8123:8123 -p 9000:9000 -p 9009:9009 --privileged=true \
-v /data/clickhouse/log:/var/log/clickhouse-server \
-v /data/clickhouse/data:/var/lib/clickhouse clickhouse/clickhouse-server:22.2.3.5
- 默认http端口是8123,tcp端口是9000, 同步端口9009
- http://IP地址:8123/play
数据类型
整型
固定长度的整型(Int8、Int16、Int32、Int64、Int128、Int256、UInt8、UInt16、UInt32、UInt64、UInt128)
浮点型(Float32 、Float64)
Decimal类型,Decimal(10,2) 小数部分2位,整数部分 8位(10-2)
UUID,通用唯一标识符(UUID)是由一组32位数的16进制数字所构成,用于标识记录
String 字符串类型
FixedString固定字符串类型(相对少用),FixedString(5)指长度为5
时间类型
- Date,日期类型,用两个字节存储,表示从 1970-01-01 (无符号) 到当前的日期值,支持字符串形式写入
- DateTime,时间戳类型。用四个字节(无符号的)存储 Unix 时间戳,支持字符串形式写入
- DateTime64,此类型允许以日期(date)加时间(time)的形式来存储一个时刻的时间值,具有定义的亚秒精度
枚举,包括
Enum8和Enum16类型,Enum保存'string'= integer的对应关系。CREATE TABLE t_enum ( page_code Enum8('home' = 1, 'detail' = 2,'pay'=3) ) ENGINE = TinyLog INSERT INTO t_enum VALUES ('home'), ('detail')
布尔值,可以使用 UInt8 类型,取值限制为 0 或 1,新增里面新增了Bool。
常用语法
## 删除数据库
DROP DATABASE xw
## 创建数据库
CREATE DATABASE xw
#建表语句
CREATE TABLE xw.test (
customer_id String,
time_stamp Date,
click_event_type String,
page_code FixedString(20),
source_id UInt64,
money Decimal(2,1),
is_new Bool
)
ENGINE = MergeTree()
ORDER BY (time_stamp)
## 查看表结构
DESCRIBE table test
## 插入数据
INSERT INTO xw.test
VALUES ('customer2', '2021-10-02', 'add_to_cart', 'home_enter', 568239,2.1, False )
##查询数据
select * from test
## 更新
ALTER TABLE xw.test UPDATE click_event_type = 'pay' where customer_id = 'customer2';
##删除
ALTER TABLE xw.test delete where customer_id = 'customer2';
## 更新和删除是异步操作,可通过下面这个语句查询执行情况
SELECT database, table, command, create_time, is_done FROM system.mutations LIMIT 20
- 更新和删除不支持事务,建议批量操作,不要高频率小数据量更新删除。
引擎
- MergeTree(合并数)。适用于高负载任务的最通用和功能最强大的表引擎。这些引擎的共同特点是可以快速插入数据并进行后续的后台数据处理。 MergeTree系列引擎支持数据复制(使用Replicated* 的引擎版本),分区和一些其他引擎不支持的其他功能。
- 日志。具有最小功能的轻量级引擎。当需要快速写入许多小表(最多约100万行)并在以后整体读取它们时,该类型的引擎是最有效的
- 集成引擎。用于与其他的数据存储与处理系统集成的引擎,包括kafka、Mysql、ODBC、JDBC、HDFS
ReplaceMergeTree
该引擎和 MergeTree 的不同之处在于它会删除排序键值相同的重复项。
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
ver— 版本列。类型为UInt*,Date或DateTime。可选参数。在数据合并的时候,
ReplacingMergeTree从所有具有相同排序键的行中选择一行留下:- 如果
ver列未指定,保留最后一条。 - 如果
ver列已指定,保留ver值最大的版本。
- 如果
实践:
create table xw.order_relace_merge_tree(
id UInt32,
sku_id String,
out_trade_no String,
total_amount Decimal(16,2),
create_time Datetime
) engine =ReplacingMergeTree(id)
order by (sku_id)
partition by toYYYYMMDD(create_time)
primary key (sku_id);
insert into xw.order_relace_merge_tree values
(1,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,
(2,'sku_2','23241',4.02,'2023-03-01 17:00:00'),
(3,'sku_3','542323',55.02,'2023-03-01 18:00:00'),
(4,'sku_5','54222',2000.3,'2023-04-01 19:00:00'),
(5,'sku_6','53423',120.2,'2023-04-01 19:00:00'),
(6,'sku_7','65432',600.01,'2023-04-02 11:00:00');
insert into xw.order_relace_merge_tree values
(11,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,
(21,'sku_2','23241',4.02,'2023-03-01 17:00:00'),
(31,'sku_3','542323',55.02,'2023-03-01 18:00:00'),
(41,'sku_5','54222',2000.3,'2023-04-01 19:00:00'),
(51,'sku_8','53423',120.2,'2023-04-01 19:00:00'),
(61,'sku_9','65432',600.01,'2023-04-02 11:00:00');
数据的去重只会在数据合并期间进行。合并会在后台一个不确定的时间进行,因此你无法预先作出计划。有一些数据可能仍未被处理。尽管可以调用 OPTIMIZE 语句发起计划外的合并,但请不要依靠它,因为 OPTIMIZE 语句会引发对数据的大量读写。。手动合并:optimize table xw.order_relace_merge_tree final;
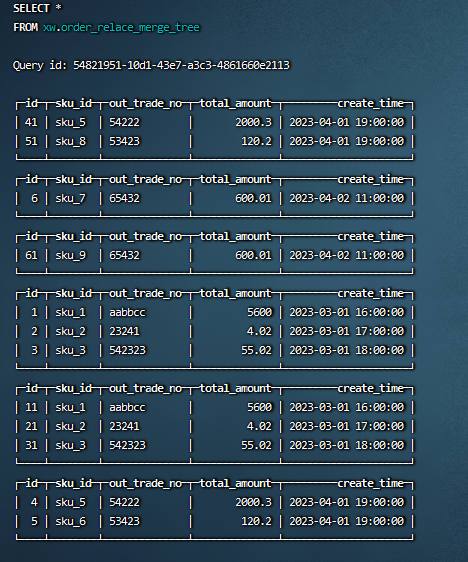
合并前:
合并后数据:
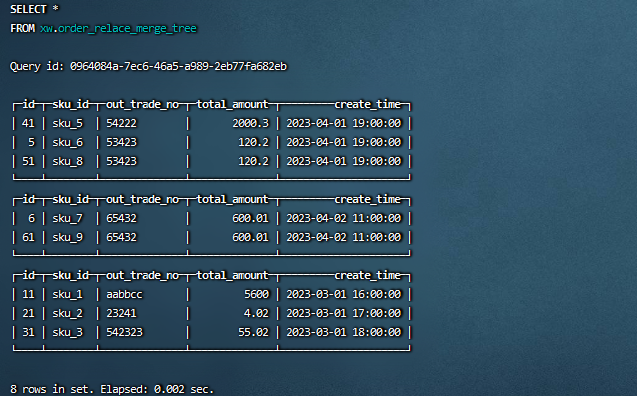
SummingMergeTree
合并 SummingMergeTree 表的数据片段时,ClickHouse 会把所有具有相同OrderBy排序键的行合并为一行,(官网描述为主键,不正确)该行包含了被合并的行中具有数值数据类型的列的汇总值。如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度。
建表语句:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = SummingMergeTree([columns])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
create table xw.order_summing_merge_tree(
id UInt32,
sku_id String,
out_trade_no String,
total_amount Decimal(16,2),
create_time Datetime
) engine =SummingMergeTree(total_amount)
order by (id,sku_id)
partition by toYYYYMMDD(create_time)
primary key (id);
## total_amount 汇总字段
## (id,sku_id) 聚合字段
insert into xw.order_summing_merge_tree values
(1,'sku_1','aabbcc',5600.00,'2023-03-01 16:00:00') ,
(2,'sku_2','23241',4.02,'2023-03-01 17:00:00'),
(3,'sku_3','542323',55.02,'2023-03-01 18:00:00'),
(4,'sku_5','54222',2000.3,'2023-04-01 19:00:00'),
(5,'sku_6','53423',120.2,'2023-04-01 19:00:00'),
(6,'sku_7','65432',600.01,'2023-04-02 11:00:00');
insert into xw.order_summing_merge_tree values
(1,'sku_1','aabbccbb',5600.00,'2023-03-01 23:09:00')
select sku_id,sum(total_amount) from xw.order_summing_merge_tree group by sku_id
## 手动合并
optimize table xw.order_summing_merge_tree final;
手动合并后结果如下,同一分区相同的排序key的被合并了:
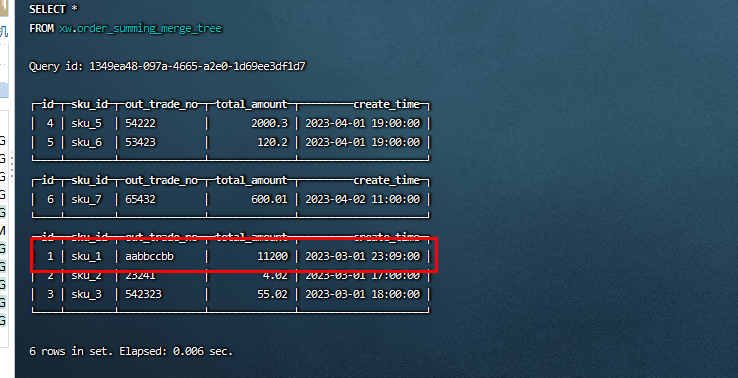
- 总结
- SummingMergeTree是根据什么对数据进行合并的
- 【ORBER BY排序键相同】作为聚合数据的条件Key的行中的列进行汇总,将这些行替换为包含汇总数据的一行记录
- 跨分区内的相同排序key的数据是否会进行合并
- 以数据分区为单位来聚合数据,同一数据分区内相同ORBER BY排序键的数据会被合并汇总,而不同分区之间的数据不会被汇总
- 如果没有指定聚合字段,会怎么聚合
- 如果没有指定聚合字段,则会用非维度列,且是数值类型字段进行聚合
- 对于非汇总字段的数据,该保留哪一条
- 如果两行数据除了【ORBER BY排序键】相同,其他的非聚合字段不相同,在聚合时会【保留最初】的那条数据,新插入的数据对应的那个字段值会被舍弃
- 在合并分区的时候按照预先定义的条件聚合汇总数据,将同一分区下的【相同排序】的多行数据汇总合并成一行,既减少了数据行节省空间,又降低了后续汇总查询的开销
- SummingMergeTree是根据什么对数据进行合并的