面经1
项目介绍
略过
如何实现服务高可用?
- 服务冗余。机器方面部署在不同机房、机柜。服务部署在不同物理机器上面
- 无状态化,无状态化的服务可实现快速扩容。
- 负载均衡,故障自动转移
- 完整的测试机制:功能测试、性能测试
- 服务限流降级熔断
- 数据主从复制,主从自动切换
CPU飙升问题排查
- 使用top命令,然后按shift+p按照cpu排序
- 使用top -H -p [进程id],找到进程中消耗资源最高的线程的id
- 将线程id转为16进制, printf "%x\n" [线程id]
- 执行 jstack [进程id] |grep -A 10 [线程id的16进制]
jdk1.8分代收集器有哪些?各自优点。
服务一两个月运行正常,CMS收集器开始频繁GC,可能的原因。
可参考https://juejin.cn/post/6844903782107578382
线程池参数?阻塞队列有哪几个类型?为什么是先放队列,满了再起空闲线程?
线程池相关代码架构:
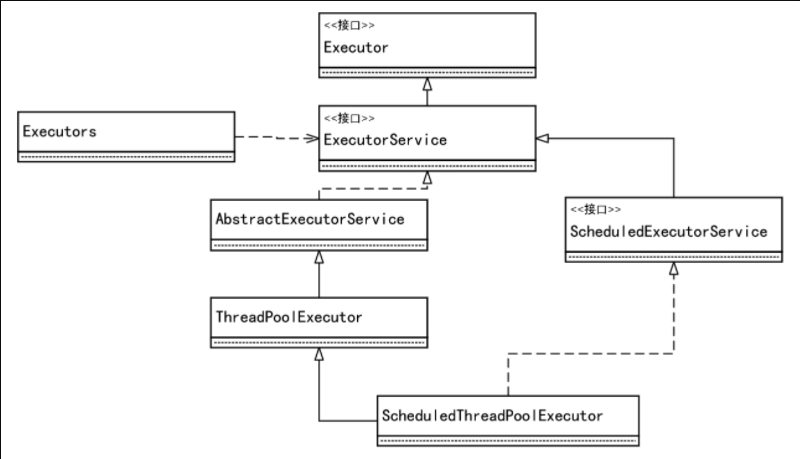
- 核心参数
- corePoolSize:核心线程数,线程池也会维护线程的最少数量,默认情况下核心线程会一直存活,即使没有任务也不会受存keepAliveTime控制,在刚创建线程池时线程不会立即启动,到有任务提交时才开始创建线程并逐步线程数目达到corePoolSize
- maximumPoolSize:线程池维护线程的最大数量,超过将被阻塞。当核心线程满,且阻塞队列也满时,才会判断当前线程数是否小于最大线程数,才决定是否创建新线程。
- keepAliveTime:非核心线程的闲置超时时间,超过这个时间就会被回收,直到线程数量等于corePoolSize。
- unit:指定keepAliveTime的单位,如TimeUnit.SECONDS、TimeUnit.MILLISECONDS
- workQueue:线程池中的任务队列,常用的如下
- ArrayBlockingQueue:是一个数组实现的有界阻塞队列(有界队列),队列中的元素按FIFO排序。ArrayBlockingQueue在创建时必须设置大小,接收的任务超出corePoolSize数量时,任务被缓存到该阻塞队列中,任务缓存的数量只能为创建时设置的大小,若该阻塞队列已满,则会为新的任务创建线程,直到线程池中的线程总数大于maximumPoolSize
- LinkedBlockingQueue,队列中的元素按FIFO排序。ArrayBlockingQueue在创建时必须设置大小,接收的任务超出corePoolSize数量时,任务被缓存到该阻塞队列中,任务缓存的数量只能为创建时设置的大小,若该阻塞队列已满,则会为新的任务创建线程,直到线程池中的线程总数大于maximumPoolSize
- SynchronousQueue,(同步队列)是一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程的调用移除操作,否则插入操作一直处于阻塞状态,其吞吐量通常高于LinkedBlockingQueue
- PriorityBlockingQueue:是具有优先级的无界队列。
- DelayQueue:这是一个无界阻塞延迟队列,底层基于PriorityBlockingQueue实现,队列中每个元素都有过期时间,当从队列获取元素(元素出队)时,只有已经过期的元素才会出队,队列头部的元素是过期最快的元素。快捷工厂方法Executors.newScheduledThreadPool所创建的线程池使用此队列。
- threadFactory:创建新线程时使用的工厂
- handler: RejectedExecutionHandler是一个接口且只有一个方法,线程池中的数量大于maximumPoolSize,对拒绝任务的处理策略,默认有4种策略
- AbortPolicy(线程池队列满了,新任务就会被拒绝,并且抛出RejectedExecutionException)
- CallerRunsPolicy(在新任务被添加到线程池时,如果添加失败,那么提交任务线程会自己去执行该任务,不会使用线程池中的线程去执行新任务)
- DiscardOldestPolicy(抛弃最老任务策略,也就是说如果队列满了,就会将最早进入队列的任务抛弃,从队列中腾出空间,再尝试加入队列。)
- DiscardPolicy(线程池队列满了,新任务就会直接被丢掉,并且不会有任何异常抛出)
任务调度
如果当前工作线程数量小于核心线程数量,执行器总是优先创建一个任务线程,而不是从线程队列获取一个空闲线程
如果线程池中总的任务数量大于核心线程池数量,新接收的任务将被加入阻塞队列中,一直到阻塞队列已满。在核心线程池数量已经用完、阻塞队列没有满的场景下,线程池不会为新任务创建一个新线程。
当完成一个任务的执行时,执行器总是优先从阻塞队列中获取下一个任务,并开始执行,一直到阻塞队列为空,其中所有的缓存任务被取光。
在核心线程池数量已经用完、阻塞队列也已经满了的场景下,如果线程池接收到新的任务,将会为新任务创建一个线程(非核心线程),并且立即开始执行新任务。
在核心线程都用完、阻塞队列已满的情况下,一直会创建新线程去执行新任务,直到池内的线程总数超出maximumPoolSize。如果线程池的线程总数超过maximumPoolSize,线程池就会拒绝接收任务,当新任务过来时,会为新任务执行拒绝策略。
具体流程图如下所示:
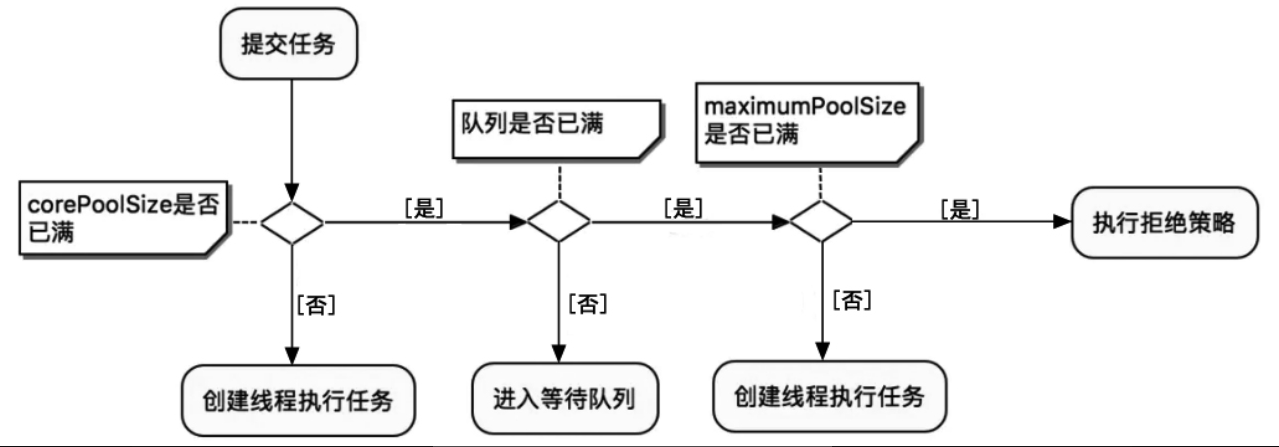
threadlocal作用,原理,内存泄露?ThreadLocal对象在方法内被final修饰值会马上释放吗?
作用:不同线程数据隔离,通过为每个线程提供一个独立的本地值去解决并发访问的冲突问题。
原理:每一个Thread线程内部都有一个Map(ThreadLocalMap),如果给一个Thread创建多个ThreadLocal实例,然后放置本地数据,那么当前线程的ThreadLocalMap中就会有多个“Key-Value对”,其中ThreadLocal实例为Key,本地数据为Value。
内存泄漏:
ThreadLocalMap是ThreadLocal的一个静态内部类,其实现了一套简单的Map结构,key为ThreadLocal实例进行包装之后的弱引用(WeakReference)。
(1)尽量使用private static final修饰ThreadLocal实例。使用private与final修饰符主要是为了尽可能不让他人修改、变更ThreadLocal变量的引用,使用static修饰符主要是为了确保ThreadLocal实例的全局唯一。
(2)ThreadLocal使用完成之后务必调用remove()方法。这是简单、有效地避免ThreadLocal引发内存泄漏问题的方法。
ThreadLocal对象在方法内被final修饰值会马上释放吗?
被final修饰的变量数据实际上存在堆上,不会马上释放。
AQS实现原理
AQS是JUC提供的一个用于构建锁和同步容器的基础类。AQS队列内部维护的是一个FIFO的双向链表,这种结构的特点是每个数据结构都有两个指针,分别指向直接的前驱节点和直接的后继节点。所以双向链表可以从任意一个节点开始很方便地访问前驱节点和后继节点。每个节点其实是由线程封装的,当线程争抢锁失败后会封装成节点加入AQS队列中;当获取锁的线程释放锁以后,会从队列中唤醒一个阻塞的节点(线程)。AQS中维持了一个单一的volatile修饰的状态信息state,AQS使用int类型的state标示锁的状态,可以理解为锁的同步状态。state因为使用volatile保证了操作的可见性,所以任何线程通过getState()获得状态都可以得到最新值。由于setState()无法保证原子性,因此AQS给我们提供了compareAndSetState()方法利用底层UnSafe的CAS机制来实现原子性。compareAndSetState()方法实际上调用的是unsafe成员的compareAndSwapInt()方法。
synchronized作用,原理实现?锁升级过程
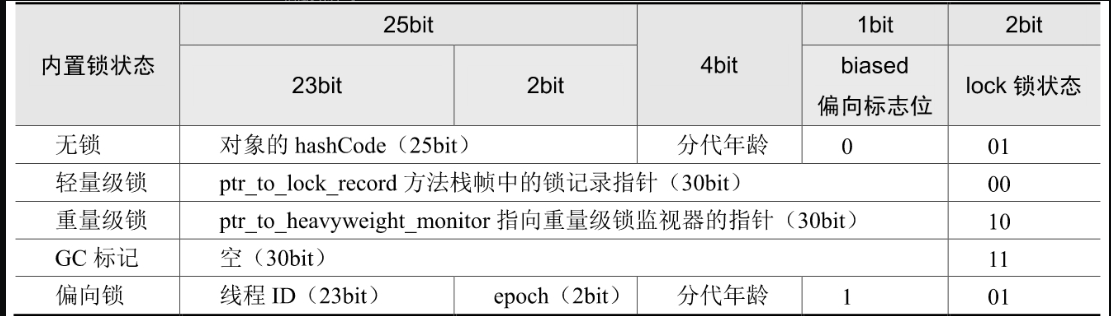
锁升级过程:
- 无锁。Java对象刚创建时还没有任何线程来竞争,说明该对象处于无锁状态(无线程竞争它)
- 偏向锁。偏向锁是指一段同步代码一直被同一个线程所访问,那么该线程会自动获取锁,降低获取锁的代价。如果内置锁处于偏向状态,当有一个线程来竞争锁时,先用偏向锁,表示内置锁偏爱这个线程,这个线程要执行该锁关联的同步代码时,不需要再做任何检查和切换。偏向锁在竞争不激烈的情况下效率非常高。
- 轻量级锁。当有两个线程开始竞争这个锁对象时,情况就发生变化了,不再是偏向(独占)锁了,锁会升级为轻量级锁,两个线程公平竞争,哪个线程先占有锁对象,锁对象的Mark Word就指向哪个线程的栈帧中的锁记录。
- 重量级锁。重量级锁会让其他申请的线程之间进入阻塞,性能降低。重量级锁也叫同步锁,这个锁对象Mark Word再次发生变化,会指向一个监视器对象,该监视器对象用集合的形式来登记和管理排队的线程。
spring怎么解决循环依赖的?
spring内部有三级缓存:
- singletonObjects 一级缓存,用于保存实例化、注入、初始化完成的bean实例
- earlySingletonObjects 二级缓存,用于保存实例化完成的bean实例
- singletonFactories 三级缓存,用于保存bean创建工厂,以便于后面扩展有机会创建代理对象。
下面用一张图告诉你,spring是如何解决循环依赖的:
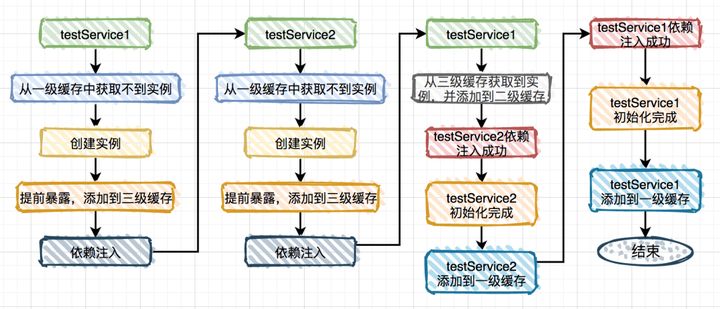
细心的朋友可能会发现在这种场景中第二级缓存作用不大。那么问题来了,为什么要用第二级缓存呢?试想一下,如果出现以下这种情况,我们要如何处理?
@Service
public class TestService1 {
@Autowired
private TestService2 testService2;
@Autowired
private TestService3 testService3;
public void test1() {
}
}
@Service
public class TestService2 {
@Autowired
private TestService1 testService1;
public void test2() {
}
}
@Service
public class TestService3 {
@Autowired
private TestService1 testService1;
public void test3() {
}
}
TestService1注入到TestService3又需要从第三级缓存中获取实例,而第三级缓存里保存的并非真正的实例对象,而是ObjectFactory对象。说白了,两次从三级缓存中获取都是ObjectFactory对象,而通过它创建的实例对象每次可能都不一样的。为了解决这个问题,spring引入的第二级缓存。上面图1其实TestService1对象的实例已经被添加到第二级缓存中了,而在TestService1注入到TestService3时,只用从第二级缓存中获取该对象即可。
Spring怎么解决事务嵌套?
事务传播。
https://docs.spring.io/spring-framework/docs/4.2.x/spring-framework-reference/html/transaction.html
spring事务失效的12种场景
事务不生效
1.方法访问权限问题,只支持public
2.方法用final修饰,动态代理不能代理final方法
3.方法内部调用,同一对象内调用没有使用代理,未被aop事务管理器控制
4.未被spring管理
5.多线程调用,事务管理内部使用threadLocal,不同线程间不在同一事务
6.表不支持事务
7.未配置事务
事务不回滚
8.错误的传播属性
9.自己吞了异常
10.手动抛了别的异常
11.自定义了回滚异常与事务回滚异常不一致
12.嵌套事务回滚多了,需要局部回滚的地方未做异常控制
注入多个user,启动指定读取某个user
@Configuration
public class UserConfig {
@Bean(name = "user1")
public User user1() {
return new User("user1");
}
@Bean(name = "user2")
public User user333() {
return new User("user2");
}
@Bean
public User user3() {
return new User("user3");
}
}
public static void main(String[] args) {
ConfigurableApplicationContext applicationContext = SpringApplication.run(TestApplication.class, args);
Object user1 = applicationContext.getBean("user2");
System.out.println(user1);
}
springcloud组件功能?
springCloud五大核心组件,五大核心组件如下:
服务发现——Netflix Eureka
负载均衡——Netflix Ribbon
断路器——Netflix Hystrix
服务网关——Netflix Zuul、gateway
分布式配置——Spring Cloud Config
spring cloud Alibaba:
- Sentinel:把流量作为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
- Nacos:一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
- RocketMQ:一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的、高可靠的消息发布与订阅服务。
- Dubbo:Apache Dubbo 是一款高性能 Java RPC 框架。
- Seata:阿里巴巴开源产品,一个易于使用的高性能微服务分布式事务解决方案。
- Alibaba Cloud OSS: 阿里云对象存储服务(Object Storage Service,简称 OSS),是阿里云提供的海量、安全、低成本、高可靠的云存储服务。您可以在任何应用、任何时间、任何地点存储和访问任意类型的数据。
- Alibaba Cloud SchedulerX: 阿里中间件团队开发的一款分布式任务调度产品,提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。
Alibaba Cloud SMS: 覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。
feign怎么替换底层httpclient?
实现Client
Feign.builder声明定义
@Import(FeignClientsConfiguration.class) class FooController { private FooClient fooClient; private FooClient adminClient; @Autowired public FooController(Client client, Encoder encoder, Decoder decoder, Contract contract, MicrometerCapability micrometerCapability) { this.fooClient = Feign.builder().client(MyClient()) .encoder(encoder) .decoder(decoder) .contract(contract) .addCapability(micrometerCapability) .requestInterceptor(new BasicAuthRequestInterceptor("user", "user")) .target(FooClient.class, "https://PROD-SVC"); this.adminClient = Feign.builder().client(MyClient()) .encoder(encoder) .decoder(decoder) .contract(contract) .addCapability(micrometerCapability) .requestInterceptor(new BasicAuthRequestInterceptor("admin", "admin")) .target(FooClient.class, "https://PROD-SVC"); } }
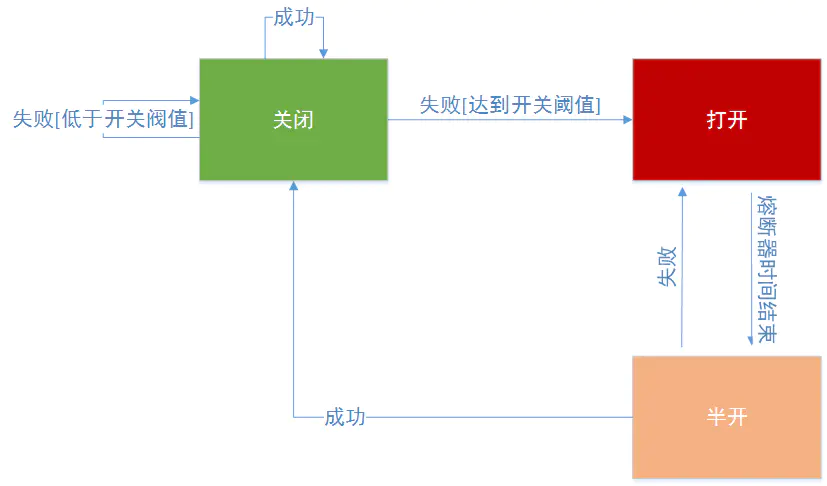
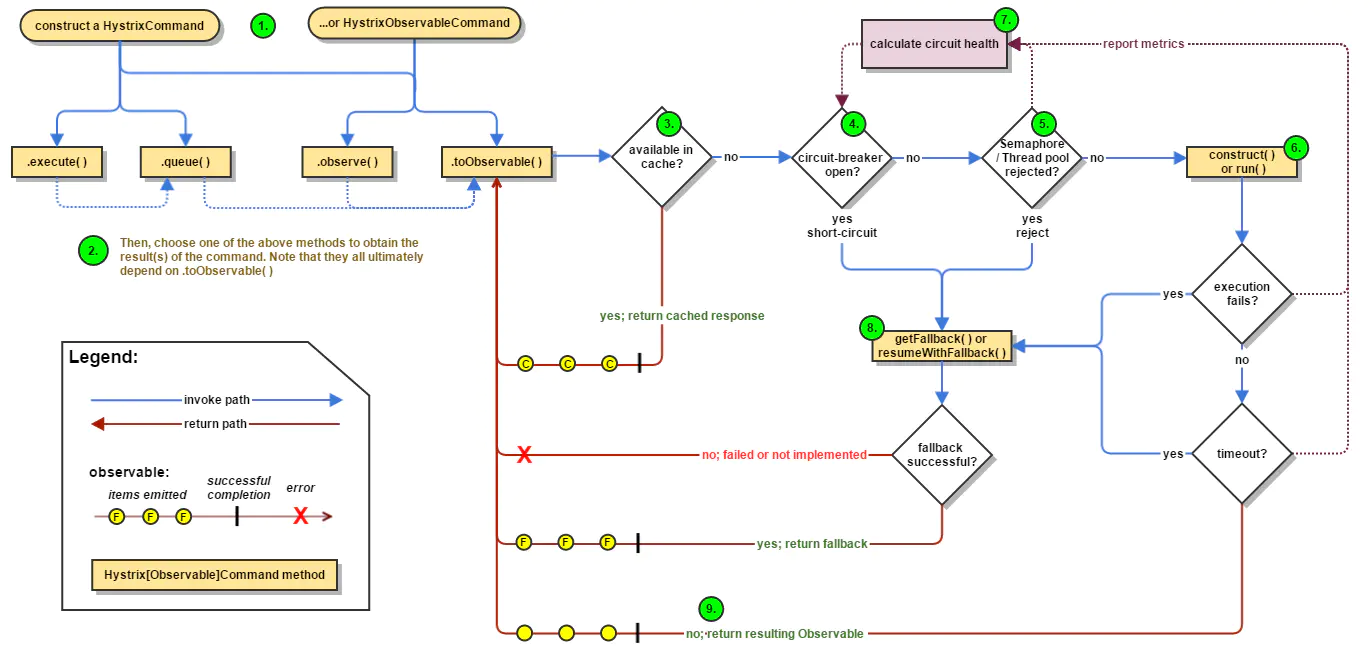
Hystrix状态的扭转?
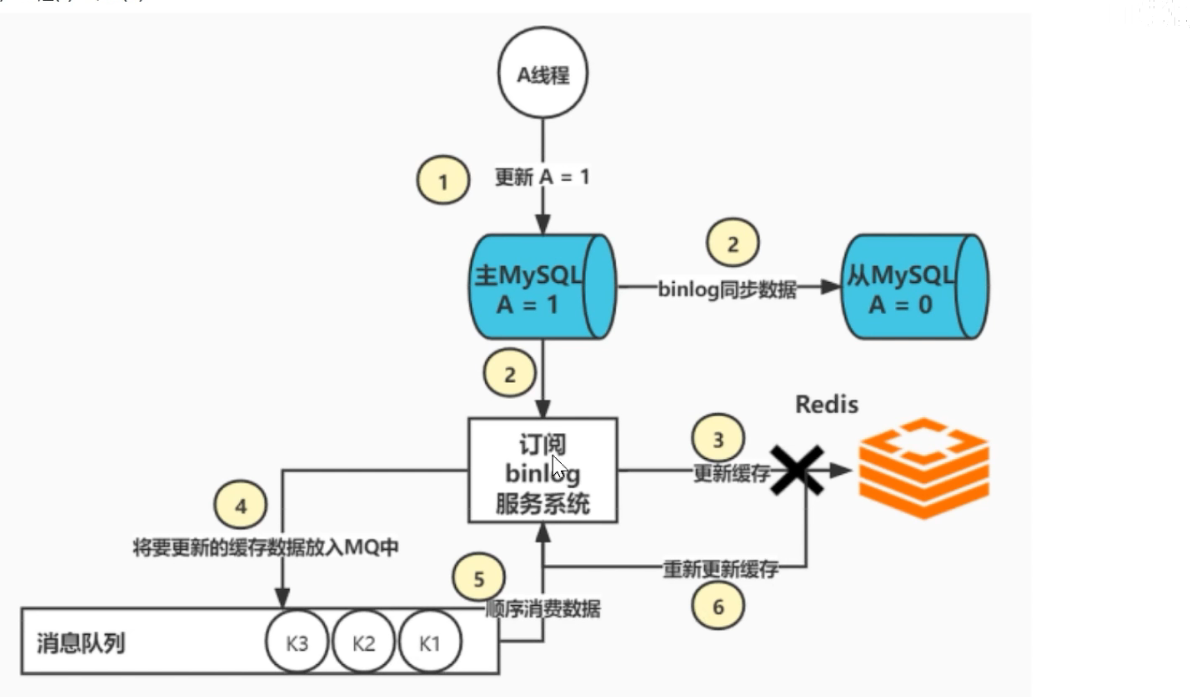
redis数据库缓存一致性处理?项目使用?双删处理,高并发情况下怎么优化?
redis缓存商品,库存很大,高并发下单,怎么处理,怎么提高并发?
将库存进行细化,商品锁力度细化,参考LongAdder
redis主从复制原理?
主从复制分两种(主从刚连接的时候,进行全量同步;全同步结束后,进行增量同步)
- 全量复制
- master服务器会开启一个后台进程用于将redis中的数据生成一个rdb文件
- 主服务器会缓存所有接收到的来自客户端的写命令,当后台保存进程 处理完毕后,会将该rdb文件传递给slave服务器
- slave服务器会将rdb文件保存在磁盘并通过读取该文件将数据加载到内存
- 在此之后master服务器会将在此期间缓存的命令通过redis传输协议发送给slave服务器
- 然后slave服务器将这些命令依次作用于自己本地的数据集上最终达到数据的一致性
- 增量复制
- Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程
- 服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令
- 全量复制
特点
- 主从复制对于 主/从 redis服务器来说是非阻塞的,所以同步期间都可以正常处理外界请求
- 一个主redis可以含有多个从redis,每个从redis可以接收来自其他从redis服务器的连接
- 从节点不会让key过期,而是主节点的key过期删除后,成为del命令传输到从节点进行删除
- 从节点开启 sync 看日志
redis list结构数据比较大,del删除,会出现什么情况?
会导致阻塞。
Redis UNLINK 命令类似与 DEL 命令,表示删除指定的 key,如果指定 key 不存在,命令则忽略。
UNLINK 命令不同与 DEL 命令在于它是异步执行的,因此它不会阻塞。
UNLINK 命令是非阻塞删除,非阻塞删除简言之,就是将删除操作放到另外一个线程去处理。
bigkeys命令查看大key
rabbit集群介绍?事务消息?
- 普通集群,他们仅有相同的元数据,即交换机、队列的结构,消息只存在其中的一个节点里面。该模式更适合于消息无需持久化的场景,如日志传输的队列
- 镜像集群,普通集群比较大的区别就是【队列queue的消息message 】会在集群各节点之间同步,且并不是在 consumer 获取数据时临时拉取,而普通集群则是临时从存储的节点里面拉取对应的数据
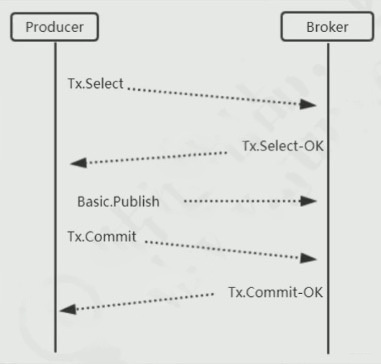
//将channel设置成事务模式
channel.txSelect();
//提交事务
channel.txCommit();
//事务回滚
channel.txRollback();
当消息的发布者在将消息发送出去之后,消息到底有没有正确到达broker代理服务器呢?如果不进行特殊配置的话,默认情况下发布操作是不会返回任何信息给生产者的,也就是默认情况下我们的生产者是不知道消息有没有正确到达broker的,如果在消息到达broker之前已经丢失的话,持久化操作也解决不了这个问题,因为消息根本就没到达代理服务器,你怎么进行持久化,那么这个问题该怎么解决呢?
RabbitMQ为我们提供了两种方式:
方式一:通过AMQP事务机制实现,这也是从AMQP协议层面提供的解决方案;
方式二:通过将channel设置成confirm模式来实现;
AMQP的事务模式是怎么使用的:
RabbitMQ中与事务机制有关的方法有三个,分别是Channel里面的txSelect(),txCommit()以及txRollback(),txSelect用于将当前Channel设置成是transaction模式,txCommit用于提交事务,txRollback用于回滚事务,在通过txSelect开启事务之后,我们便可以发布消息给broker代理服务器了,如果txCommit提交成功了,则消息一定是到达broker了,如果在txCommit执行之前broker异常奔溃或者由于其他原因抛出异常,这个时候我们便可以捕获异常通过txRollback回滚事务了。
mysql是怎么进行事务回滚的?
undo log,过程如下:

mysql隔离级别怎么实现的?
对于使用READ UNCOMMITTED隔离级别的事务来说,由于可以读到未提交事务修改过的记录,所以直接读取记录的最新版本就好了;对于使用SERIALIZABLE隔离级别的事务来说,设计InnoDB的大叔规定使用加锁的方式来访问记录(加锁是啥我们后续文章中说哈);对于使用READ COMMITTED和REPEATABLE READ隔离级别的事务来说,都必须保证读到已经提交了的事务修改过的记录,也就是说假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的,核心问题就是:需要判断一下版本链中的哪个版本是当前事务可见的。为此,设计InnoDB的大叔提出了一个ReadView的概念,这个ReadView中主要包含4个比较重要的内容:
m_ids:表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。min_trx_id:表示在生成ReadView时当前系统中活跃的读写事务中最小的事务id,也就是m_ids中的最小值。max_trx_id:表示生成ReadView时系统中应该分配给下一个事务的id值。
小贴士: 注意max_trx_id并不是m_ids中的最大值,事务id是递增分配的。比方说现在有id为1,2,3这三个事务,之后id为3的事务提交了。那么一个新的读事务在生成ReadView时,m_ids就包括1和2,min_trx_id的值就是1,max_trx_id的值就是4。creator_trx_id:表示生成该ReadView的事务的事务id。
小贴士: 我们前边说过,只有在对表中的记录做改动时(执行INSERT、DELETE、UPDATE这些语句时)才会为事务分配事务id,否则在一个只读事务中的事务id值都默认为0。
有了这个ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
- 如果被访问版本的
trx_id属性值与ReadView中的creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。 - 如果被访问版本的
trx_id属性值小于ReadView中的min_trx_id值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。 - 如果被访问版本的
trx_id属性值大于或等于ReadView中的max_trx_id值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。 - 如果被访问版本的
trx_id属性值在ReadView的min_trx_id和max_trx_id之间,那就需要判断一下trx_id属性值是不是在m_ids列表中,如果在,说明创建ReadView时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。
mysql锁?
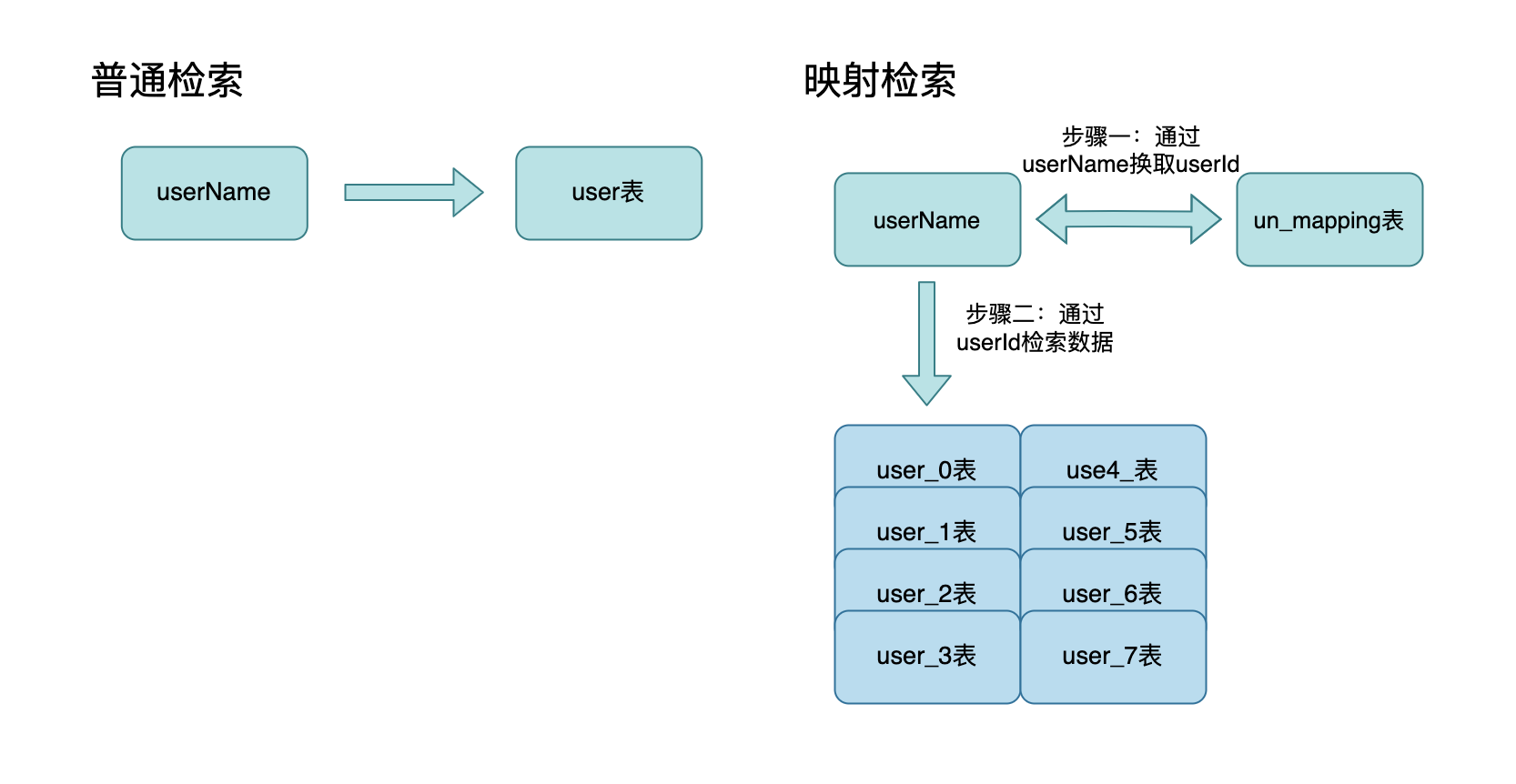
分库分表非partion key查询
- 对于单个非partition key查询一般可以根据业务场景需要解决方案
- 映射法检索,通过非partition key找到对应的partition key,再根据partition key做hash找到对应库表
- 优点:方案简单清晰
- 缺点:需要检索两次数据库,消耗IO较大
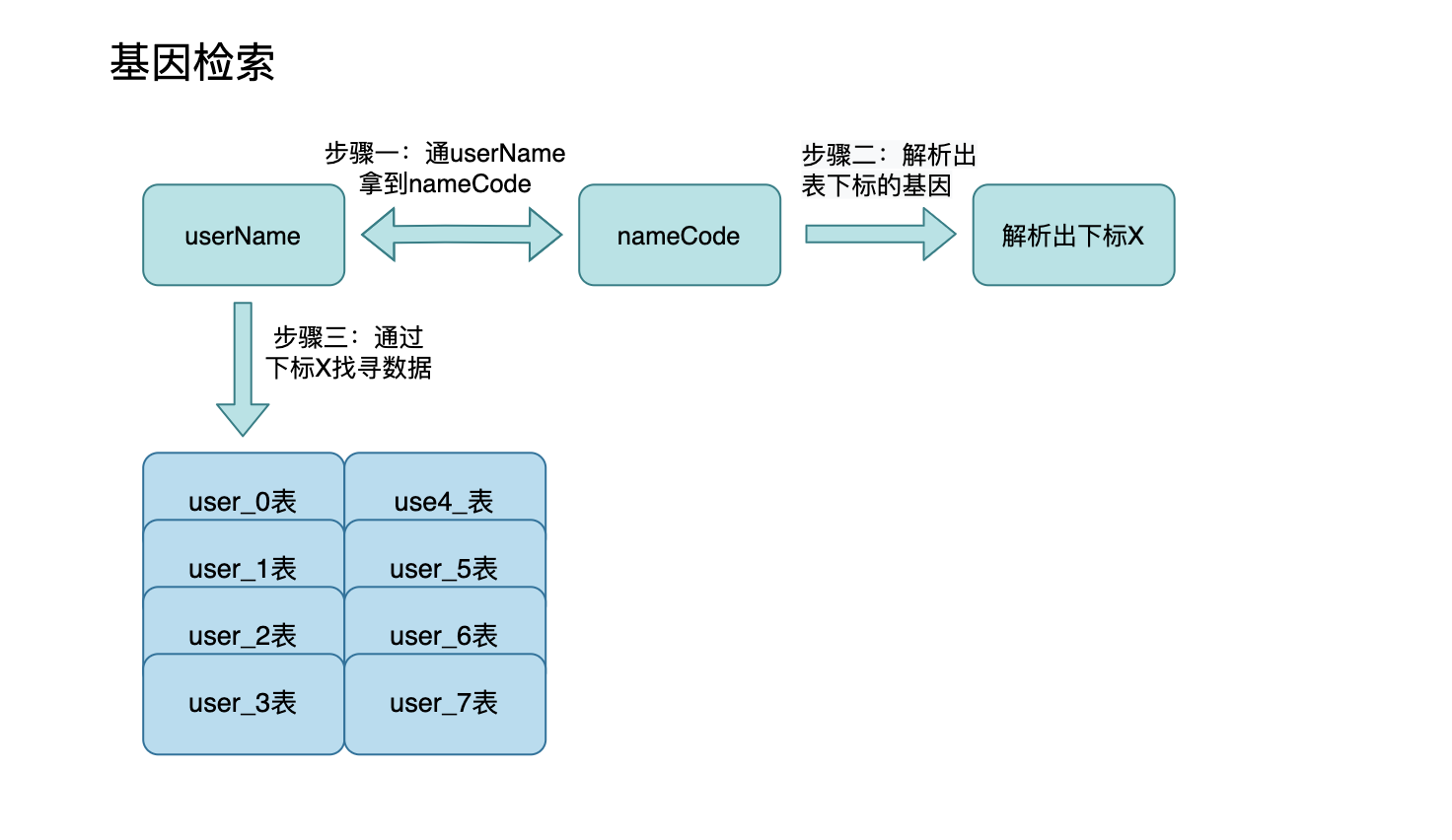
- 基因法检索,在存储非partition key时冗余一个字段用于预埋能找到对应的partition key,再根据partition key做hash找到对应库表
- 优点:建立冗余字段,只需要解析基因即可
- 缺点:需要设置基因解析逻辑
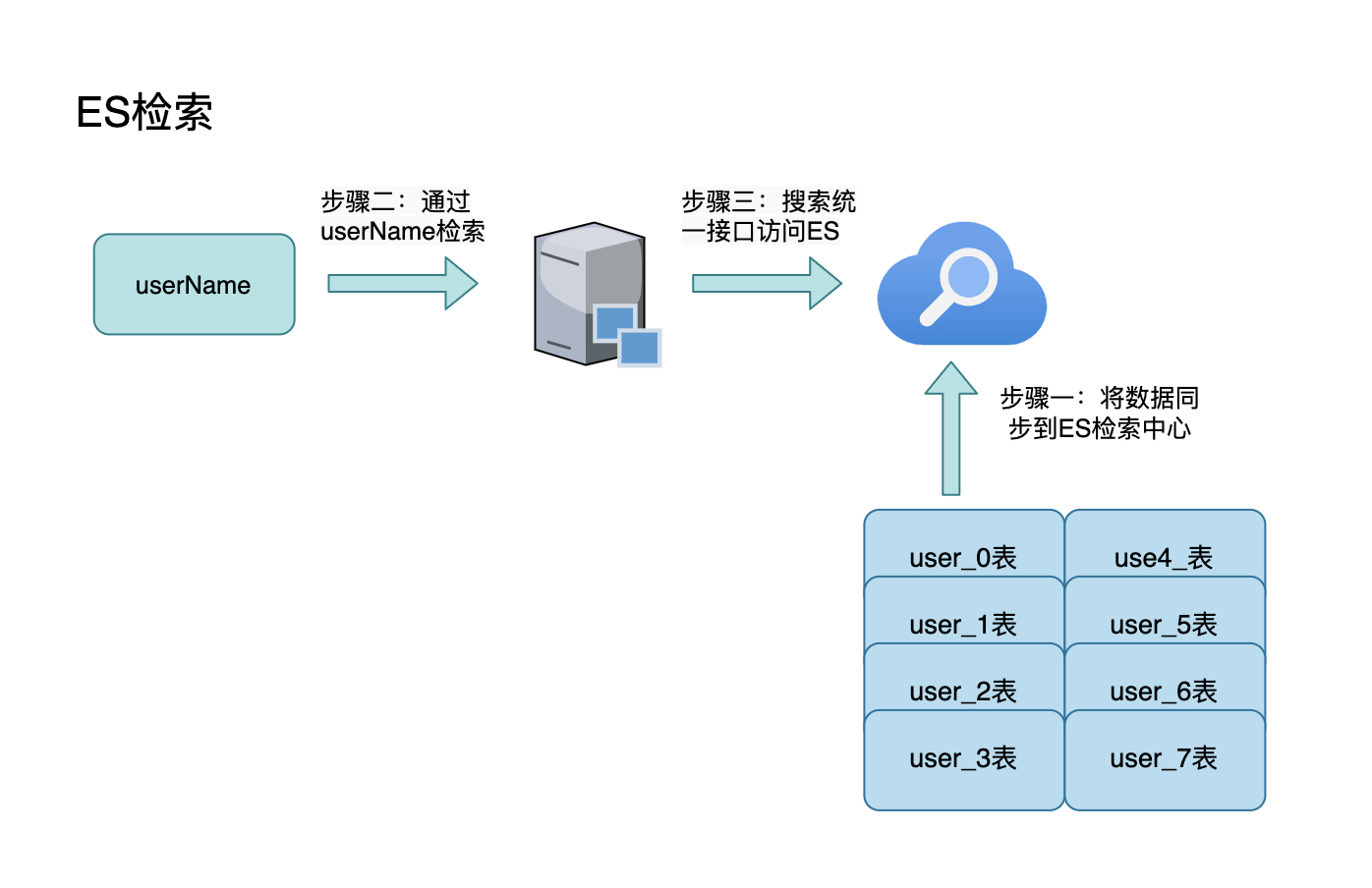
- ES检索,根据非partition key作为条件建立起检索,后续查询直接走异构系统ES即可,性能和稳定性由ES保证
- 优点:性能高,能支撑高并发访问和多条件检索
- 缺点:开发成本增加,需要维护第三方组件
- 映射法检索,通过非partition key找到对应的partition key,再根据partition key做hash找到对应库表
分库跨库join?
同服务器的不同库:只需要在表名前加上db_name
不同服务器不同库:查看配置 FEDERATED,在本地库创建相同的表建立连接
SHOW engines;
CREATE TABLE `order` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` bigint NOT NULL,
`product_name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE =FEDERATED CONNECTION='mysql://root:123456@192.168.10.100:3306/orderdb/order';
生产环境不推荐使用!!!!!!!
开十个线程执行任务,执行完成后继续运行主线程,怎么实现?底层原理是什么?
可以使用CountDownLatch实现。
底层还是通过AQS实现。