面经2
bootstrap.yml和application.yml加载顺序?同名属性会被覆盖吗?
bootstrap.yml比application.yml先进行加载,bootstrap.yml一般在spring cloud中作为引导类,如不引入spring-cloud-context依赖,bootstrap.yml不会被加载。同名属性会被覆盖掉。
给你一个Maven镜像,一份maven工程java源代码,一个OpenJdk镜像,在一个Dockerfile中构建出来需要的镜像
## 步骤1,通过maven打包jar包
FROM maven:3.8.6-openjdk-18-slim AS build-stage
add demo1 /var/demo1/
RUN cd /var/demo1 && mvn install
## 启动
FROM circleci/jdk8:0.1.1
COPY --from=build-stage /root/.m2/repository/com/example/demo1/0.0.1-SNAPSHOT/demo1-0.0.1-SNAPSHOT.jar /data/app.jar
ENTRYPOINT ["java","-jar","/data/app.jar"]
使用多步骤构建,第二个基础镜像会覆盖掉第一个,使用COPY --from复制第一个步骤的jar包,参考链接
kafka和RabbitMq有哪些区别你知道吗?
架构区别:
rabbitmq
kafka:
消费:
rabbitmq使用推模式,kafka使用拉模式。
Kafka使用拉模型。使用者请求来自特定偏移量的批消息。Kafka在没有竞争消费者的分区中提供消息顺序。这允许用户利用消息的批处理来实现有效的消息传递和更高的吞吐量。
RabbitMQ使用推模型,并通过在消费者上定义的预取限制来阻止过度消费。这可以用于低延迟消息传递。推模型的目的是独立且快速地分发消息,以确保工作被均匀地并行化,并且消息的处理顺序大致与它们到达队列的顺序一致。但是,当一个或多个消费者死亡且不再接收消息时,这也会导致问题。
性能:
Kafka提供的性能比RabbitMQ更高。它使用顺序磁盘I/O来提高性能,可以使用有限的资源实现高吞吐量。
RabbitMQ每秒也可以处理100万条消息,但需要更多的资源。
使用场景:
kafka:
- 高吞吐量场景
- 数据流场景
- 顺序消费
rabbitmq:
- 延时队列
- 需要各种发布/订阅,点对点请求/回复消息传递功能的应用程序。
kafka高吞吐量的原因,在设计层面做了哪些优化?
- 顺序读写
- 页缓存
- 零拷贝
- 分区分段+索引
- 批量读写
- 批量压缩
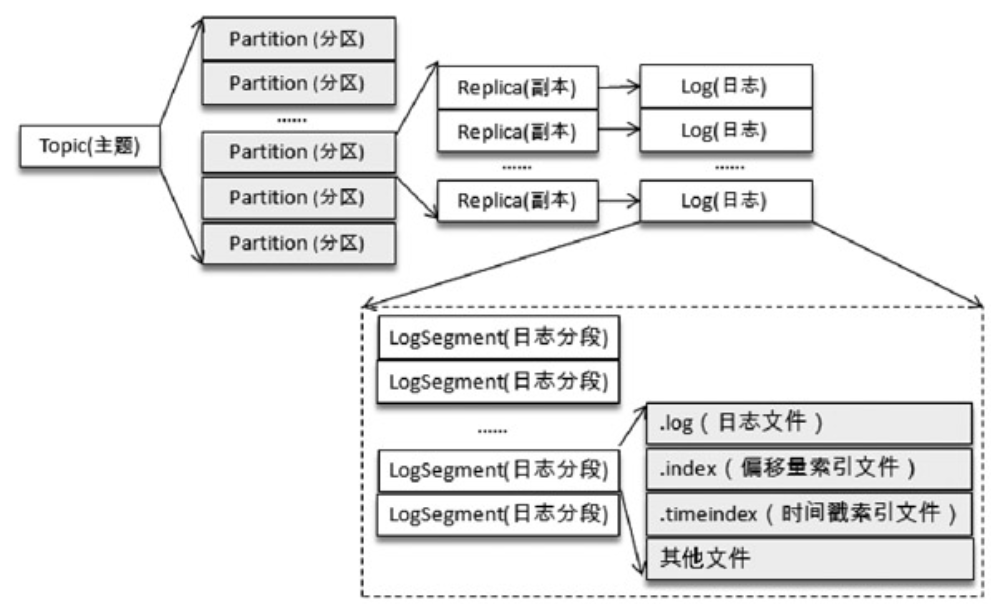
kafka消息底层数据结构
Kafka 中的消息是以主题为基本单位进行归类的,各个主题在逻辑上相互独立。每个主题又可以分为一个或多个分区,分区的数量可以在主题创建的时候指定,也可以在之后修改。每条消息在发送的时候会根据分区规则被追加到指定的分区中,分区中的每条消息都会被分配一个唯一的序列号,也就是通常所说的偏移量(offset)。
一个分区对应一个日志(Log)。为了防止 Log 过大,Kafka又引入了日志分段(LogSegment)的概念,将Log切分为多个LogSegment,相当于一个巨型文件被平均分配为多个相对较小的文件,这样也便于消息的维护和清理。事实上,Log 和LogSegment 也不是纯粹物理意义上的概念,Log 在物理上只以文件夹的形式存储,而每个LogSegment 对应于磁盘上的一个日志文件和两个索引文件。
为了便于消息的检索,每个LogSegment中的日志文件(以“.log”为文件后缀)都有对应的两个索引文件:偏移量索引文件(以“.index”为文件后缀)和时间戳索引文件(以“.timeindex”为文件后缀)。每个 LogSegment 都有一个基准偏移量 baseOffset,用来表示当前 LogSegment中第一条消息的offset。偏移量是一个64位的长整型数,日志文件和两个索引文件都是根据基准偏移量(baseOffset)命名的,名称固定为20位数字,没有达到的位数则用0填充。比如第一个LogSegment的基准偏移量为0,对应的日志文件为00000000000000000000.log。
Springboot的启动过程
rabbitmq怎么保证消息的可靠性
生产者消费者ACK,broker做镜像集群。
kafka hw
HW作用:保证消费数据的一致性和副本数据的一致性
- HW机制概述
- LEO:表示每个partition的log最后一条Message的位置
- HW:表示partition各个replicas数据见同步且一致的offset位置
Flink算子
Flink故障怎么恢复有了解吗
Fink时间概念
事件时间EventTime(重点关注)
- 事件发生的时间
- 事件时间是每个单独事件在其产生进程上发生的时间,这个时间通常在记录进入 Flink 之前记录在对象中
- 在事件时间中,时间值 取决于数据产生记录的时间,而不是任何Flink机器上的
进入时间 IngestionTime
- 事件到进入Flink
处理时间ProcessingTime
事件被flink处理的时间
指正在执行相应操作的机器的系统时间
是最简单的时间概念,不需要流和机器之间的协调,它提供最佳性能和最低延迟
但是在分布式和异步环境中,处理时间有不确定性,存在延迟或乱序问题
RabbitMq集群,有什么优缺点?
分为普通集群和镜像集群,
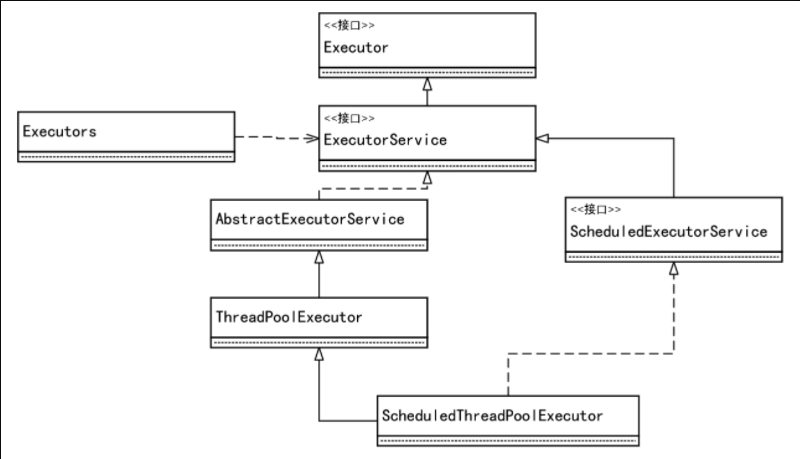
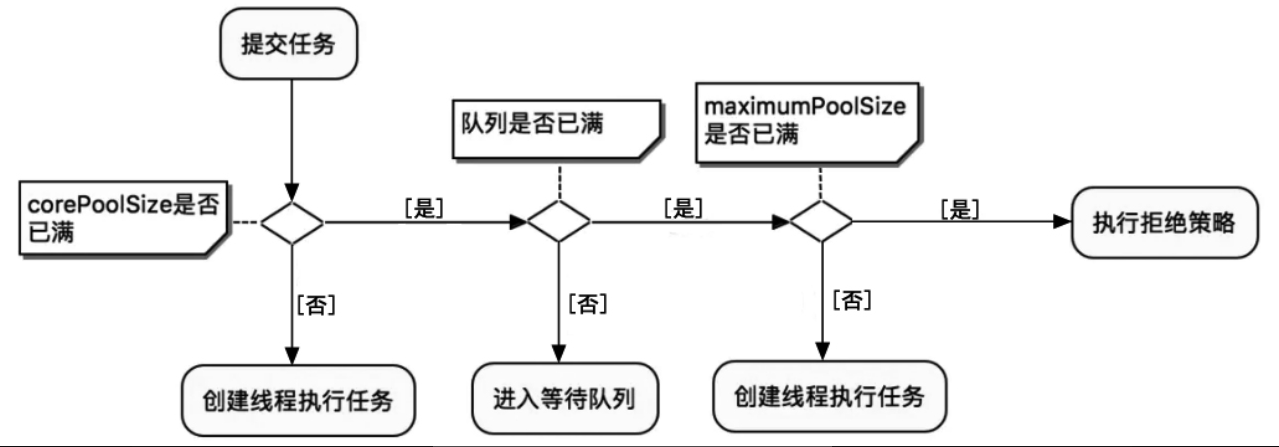
线程池有哪些参数,运行机制是怎么样的?
线程池相关代码架构:
- 核心参数
- corePoolSize:核心线程数,线程池也会维护线程的最少数量,默认情况下核心线程会一直存活,即使没有任务也不会受存keepAliveTime控制,在刚创建线程池时线程不会立即启动,到有任务提交时才开始创建线程并逐步线程数目达到corePoolSize
- maximumPoolSize:线程池维护线程的最大数量,超过将被阻塞。当核心线程满,且阻塞队列也满时,才会判断当前线程数是否小于最大线程数,才决定是否创建新线程。
- keepAliveTime:非核心线程的闲置超时时间,超过这个时间就会被回收,直到线程数量等于corePoolSize。
- unit:指定keepAliveTime的单位,如TimeUnit.SECONDS、TimeUnit.MILLISECONDS
- workQueue:线程池中的任务队列,常用的如下
- ArrayBlockingQueue:是一个数组实现的有界阻塞队列(有界队列),队列中的元素按FIFO排序。ArrayBlockingQueue在创建时必须设置大小,接收的任务超出corePoolSize数量时,任务被缓存到该阻塞队列中,任务缓存的数量只能为创建时设置的大小,若该阻塞队列已满,则会为新的任务创建线程,直到线程池中的线程总数大于maximumPoolSize
- LinkedBlockingQueue,队列中的元素按FIFO排序。ArrayBlockingQueue在创建时必须设置大小,接收的任务超出corePoolSize数量时,任务被缓存到该阻塞队列中,任务缓存的数量只能为创建时设置的大小,若该阻塞队列已满,则会为新的任务创建线程,直到线程池中的线程总数大于maximumPoolSize
- SynchronousQueue,(同步队列)是一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程的调用移除操作,否则插入操作一直处于阻塞状态,其吞吐量通常高于LinkedBlockingQueue
- PriorityBlockingQueue:是具有优先级的无界队列。
- DelayQueue:这是一个无界阻塞延迟队列,底层基于PriorityBlockingQueue实现,队列中每个元素都有过期时间,当从队列获取元素(元素出队)时,只有已经过期的元素才会出队,队列头部的元素是过期最快的元素。快捷工厂方法Executors.newScheduledThreadPool所创建的线程池使用此队列。
- threadFactory:创建新线程时使用的工厂
- handler: RejectedExecutionHandler是一个接口且只有一个方法,线程池中的数量大于maximumPoolSize,对拒绝任务的处理策略,默认有4种策略
- AbortPolicy(线程池队列满了,新任务就会被拒绝,并且抛出RejectedExecutionException)
- CallerRunsPolicy(在新任务被添加到线程池时,如果添加失败,那么提交任务线程会自己去执行该任务,不会使用线程池中的线程去执行新任务)
- DiscardOldestPolicy(抛弃最老任务策略,也就是说如果队列满了,就会将最早进入队列的任务抛弃,从队列中腾出空间,再尝试加入队列。)
- DiscardPolicy(线程池队列满了,新任务就会直接被丢掉,并且不会有任何异常抛出)
任务调度
如果当前工作线程数量小于核心线程数量,执行器总是优先创建一个任务线程,而不是从线程队列获取一个空闲线程
如果线程池中总的任务数量大于核心线程池数量,新接收的任务将被加入阻塞队列中,一直到阻塞队列已满。在核心线程池数量已经用完、阻塞队列没有满的场景下,线程池不会为新任务创建一个新线程。
当完成一个任务的执行时,执行器总是优先从阻塞队列中获取下一个任务,并开始执行,一直到阻塞队列为空,其中所有的缓存任务被取光。
在核心线程池数量已经用完、阻塞队列也已经满了的场景下,如果线程池接收到新的任务,将会为新任务创建一个线程(非核心线程),并且立即开始执行新任务。
在核心线程都用完、阻塞队列已满的情况下,一直会创建新线程去执行新任务,直到池内的线程总数超出maximumPoolSize。如果线程池的线程总数超过maximumPoolSize,线程池就会拒绝接收任务,当新任务过来时,会为新任务执行拒绝策略。
具体流程图如下所示:
Redis持久化方式
RDB的优点:
- RDB文件非常紧凑,节省内存空间;
- RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快;
- 适合全量备份、全量复制的场景,经常用于灾难恢复(对数据的完整性和一致性要求相对较低的场合)
RDB的缺点:
- 服务器宕机时,可能会丢失部分数据;
- 每次保存RDB的时候,Redis都要fork出一个子进程,这个过程是阻塞的,如果数据集巨大,那阻塞的时间就会很长。
AOF的优点:
- 数据更加完整,丢失数据的可能性较低;
- AOF日志文件可读,并且可以对AOF文件修复。
AOF的缺点:
- AOF日志记录在长期运行中逐渐庞大,恢复起来非常耗时,需要定期对AOF日志进行瘦身处理;
- 恢复备份速度比较慢。
在redis4.x版本支持RDB和AOF共用。
Redis如何实现分布式锁
~~
@Service注解和@Component注解有什么区别
@Component注解表明一个类会作为组件类,并告知Spring要为这个类创建bean。
@Service标记bean,以表明它们持有业务逻辑。一般在服务层中使用。
@Repository捕获特定于持久性的异常,并将其作为Spring统一的未检查异常之一重新抛出。