Linux性能问题排查
CPU使用率高排查
- 使用top命令,然后按shift+p按照cpu排序
- 使用top -H -p [进程id],找到进程中消耗资源最高的线程的id
- 将线程id转为16进制, printf "%x\n" [线程id]
- 执行 jstack [进程id] |grep -A 10 [线程id的16进制]
linux压测和性能排查工具
目标:分析Linux相关性能指标,找出CPU平均负载升高的进程和原因。常见的原因有多个进程争夺CPU、等待IO、CPU上下文切换。
sysstat工具包的命令mpstat+pidsat
- 命令:mpstat(全局)多核CPU性能分析程序,实时查看每个CPU的性能指标和全部CPU的平均性能指标
- 命令:pidstat(局部)实时查看进程的CPU、内存、I/O、上下文切换等指标
- 命令:vmstat(全局)实时查看系统的上下文切换(跨进程间,同个进程里多个子线程)、系统中断次数
安装:
下载安装包:https://github.com/sysstat/sysstat/releases/tag/v12.7.5
执行以下安装命令
yum install gcc -y yum install unzip -y unzip sysstat-12.7.5.zip cd sysstat-12.7.5 ./configure make sudo make install pidstat -vmpstat命令:
使用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大还是IO压力增大的情况导致。
语法:
mpstat [-P {cpu|ALL}] [interval [count]]-P {cpu|ALL}:指定要监控的 CPU。CPU 编号范围从 0 到总 CPU 数量减 1。interval:连续采样之间的时间间隔。count:采样次数(与interval一起使用)。
用法示例:
要每 2 秒查看所有 CPU 核心的当前状态:
mpstat这将提供 CPU 使用率的概览,包括用户、系统、空闲和其他状态。
要查看每个 CPU 核心的详细实时信息:
mpstat -P ALL 2输出将显示各个核心的统计数据,包括用户、系统和空闲百分比。
输出字段:
%usr:在间隔内的用户态 CPU 时间。%nice:具有负 nice 值的进程的 CPU 时间。%sys:内核(系统)时间。%iowait:等待 I/O 操作的时间。%irq:处理硬件中断的时间。%soft:处理软件中断的时间。%idle:空闲时间(不包括 I/O 等待)。
pidstat命令:
pidstat 是 sysstat 工具的一部分,用于监控全部或指定进程的 CPU、内存、线程、设备 I/O 等系统资源的占用情况。它提供了关于进程性能的详细信息。以下是一些常用的 pidstat 参数和示例:
查看所有进程的 CPU 使用情况(默认参数
-u):pidstat这将显示各个进程的 CPU 使用率,包括用户态、内核态和虚拟机占用的百分比。
查看各活动进程的内存使用情况(参数
-r):pidstat -r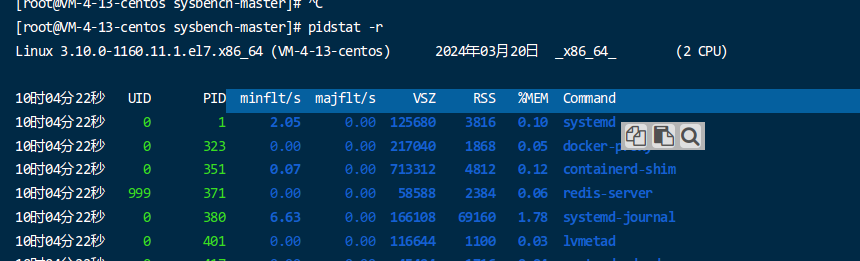
输出包括进程标识符、每秒发生的次要错误、每秒发生的主要错误、虚拟地址大小、常驻集合大小等。
- minflt/s:每秒发生的次要页面错误(minor page faults)的数量。次要页面错误发生在进程访问当前不在物理 RAM(主内存)中的内存页面时。操作系统随后从磁盘或交换空间中检索所需的页面。次要页面错误在性能影响方面相对较低。
- majflt/s:每秒发生的主要页面错误(major page faults)的数量。主要页面错误发生在进程访问不仅在 RAM 中缺失,而且还需要从磁盘或交换空间加载的内存页面时。主要页面错误在性能方面的成本较高,因为它涉及磁盘 I/O。
- VSZ(虚拟内存大小):这是进程使用的总虚拟内存。它包括实际物理内存(RSS)和任何交换到磁盘的内存(如果适用)。VSZ 表示为进程保留的整个地址空间,包括映射的内存和其他资源。
- RSS(常驻集合大小):RSS 表示当前在物理 RAM(常驻内存)中的进程内存部分。它不包括任何交换出的内存。RSS 是了解进程实际内存使用情况的关键指标。
- %MEM:这个百分比表示进程的 RSS 占用的物理 RAM 的比例(作为总系统内存的一部分)。它提供了相对于系统容量的快速内存使用概览。
- Command:此字段显示与资源使用相关联的进程或命令的名称。
显示各个进程的 I/O 使用情况(参数
-d):pidstat -d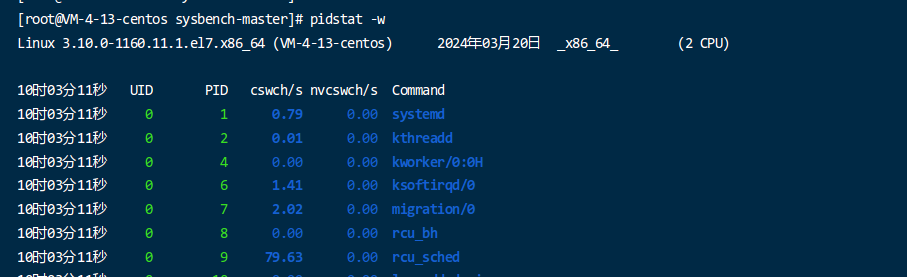
输出包括进程 ID、每秒从磁盘读取的 KB、每秒写入磁盘的 KB 等。
- cswch/s(主动上下文切换):这是指操作系统在每秒内主动切换进程的次数。主动上下文切换通常发生在进程主动放弃 CPU 使用权,例如等待 I/O 操作、等待资源、进程时间片用完等情况。主动上下文切换的数量越高,表示系统中有更多的进程在竞争 CPU 资源。
- nvcswch/s(被动上下文切换):这是指操作系统在每秒内由于其他原因(如硬件中断、时钟中断等)而切换进程的次数。被动上下文切换通常是由于外部事件触发,而不是进程主动放弃 CPU。被动上下文切换的数量也会影响系统的性能。
显示每个进程的上下文切换情况(参数
-w):pidstat -w -p 2831输出包括进程 ID、每秒主动任务上下文切换数量、被动任务上下文切换数量等。
显示选择任务的线程的统计信息外的额外信息(参数
-t):pidstat -t -p 2831
f.输出顺序
输出包括主线程的表示、线程 ID、CPU 使用率、命令名等。
模拟工具:
stress多进程工具,模拟IO密集型应用、CPU密集型应用、多进程等待CPU调度场景,对内存、CPU、io等情况进行压测。
安装命令:
yum install -y epel-release yum install stress -y安装结果
参数说明
参数 说明 --timeout 指定运行多少秒 --cpu N 产生多个处理sync函数的CPU进程,每个进程高频的计算随机数的平方根,模拟CPU计算密集型场景 --io N 产生多个处理sync函数的磁盘/O进程,每个进程高频调用syc0,刷内存缓冲区到磁盘,模拟IVO密集型场景 --vm N 每个进程高频调用内存分配malloc()和内存释放free()函数 --vm-bytes 指定malloc0时申请内存的字节数,默认256MB -hdd N 产生N个高频执行write和unlink函数的进程(创建/写入/删除文件),属于磁盘IO进程 --hdd-bytes 每个hdd workeri进程写的byte数,默认1G 需求一:模拟CPU密集型应用,系统是4核
- 终端一模拟两个CPU核的使用率100%,对2个Cpu进行压力测试持续600S
stress --cpu 2 --timeout 600 - 终端二-d参数表示高亮显示变化的区域
watch-d uptime - 终端三mpstat查看CPU使用率情况,每5秒监控所有CPU情况
mpstat-p ALL 5 - 终端四查看运行中的进程和任务,每5秒刷新一次
pidstat-u 5
- 终端一模拟两个CPU核的使用率100%,对2个Cpu进行压力测试持续600S
sysbench多线程基准测试工具,模拟上下文切换过多场景。
安装命令
yum -y install make automake libtool pkgconfig libaio-devel yum -y install mariadb-devel openssl-devel yum -y install postgresql-devel unzip sysbench-master.zip cd sysbench-master ./autogen.sh ./configure --without-mysql make && make install sysbench --version需求:大量等待CPU的进程调度导致平均负载升高
- 终端一模拟8个进程,也可以更多,持续600S。
stress --cpu 8 --timeout 600s - 终端二-d参数表示高亮显示变化的区域
watch-d uptime - 终端三mpstat查看CPU使用率情况,每S秒监控所有CPU情况
mpstat-P ALL 2 3每隔2秒出一个报告数据,一共出具3
次 - 终端四查看运行中的进程和任务,每5秒刷新一次
pidstat -u2 3每隔2秒出一个报告数据,一共出具3次
- 终端一模拟8个进程,也可以更多,持续600S。
详细分析思路
- 全局
- uptime:运行1分钟后,4个核的CPU负载是比较高
- mpstat:
- 应用场景:当系统变慢,CPU平均负载增大时,判断是CPU的使用率增大,还是IO压力增大的情况导致
- 多次调用mpstat,.持续观察,平均负载升高,每个cpu利用率都高,使用率接近100%,iowait很低接近0,IO不是瓶颈
- 再进一步分析,CPU利用率高,主要是哪部分操作占据了CPU
- 局部
- pidstat:对进程和任务的使用情况进行,发现%wait高,说明cpu不够用在等待cpu调度上花费了不少时间
- 结论:8个进程在竞争4个cpu,每个进程等待cpu的时间达到50%(%wit),超出cpu计算能力的进程,导致了负载变高
pidstat -uCPU情况,默认pidstat -d磁盘IO情况,基本很低- 举一反三:如果不是stress,其他进程造成这类影响的,靠这个思路也能排查出是哪个进程。
- 全局