io模型
大约 3 分钟LinuxLinux
基本过程
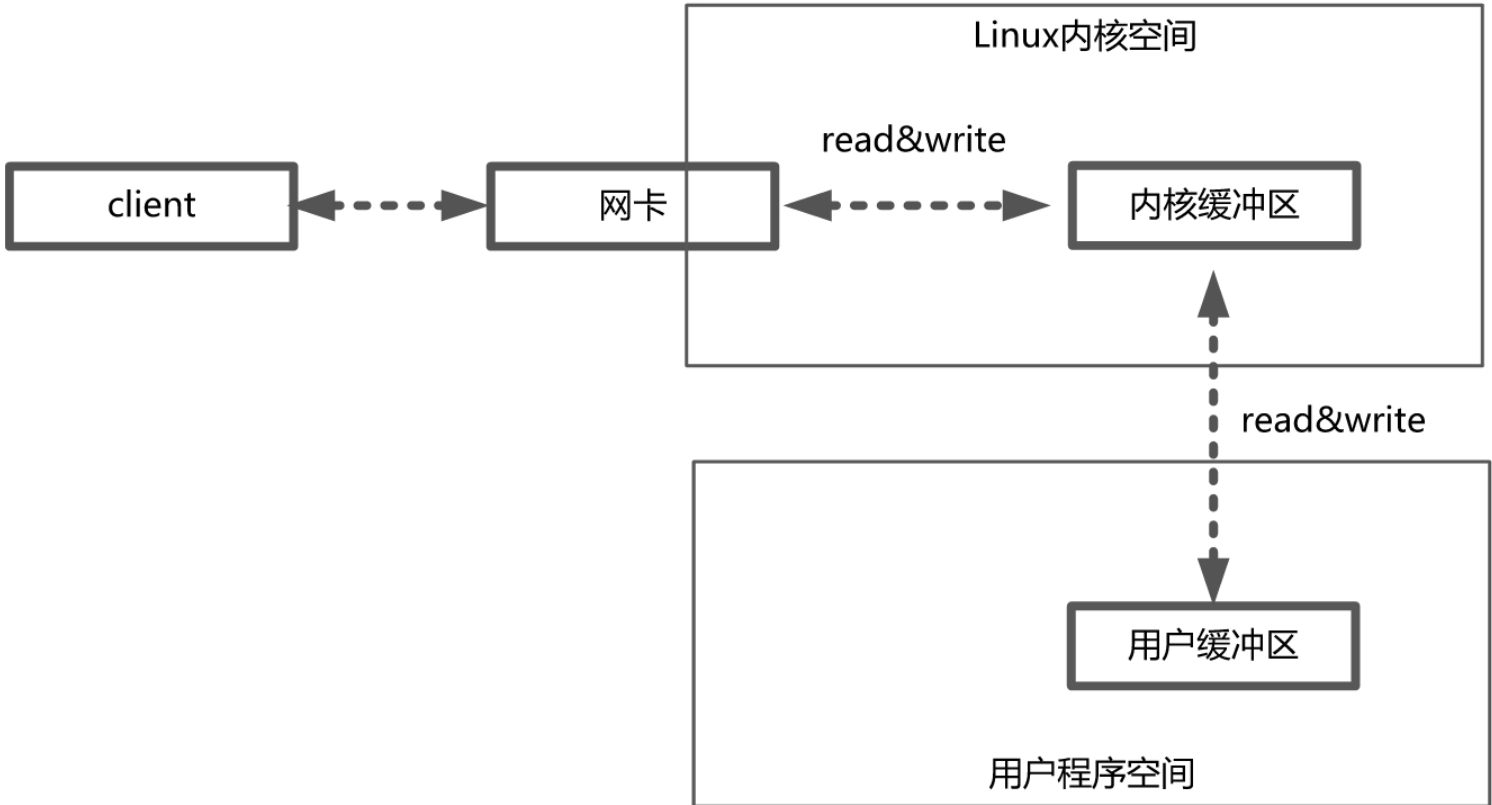
如图所示,以读取数据为例,数据经网卡后复制到内核缓冲区后,将内核缓冲区的数据复制到用户缓冲区供程序读取。
IO类型
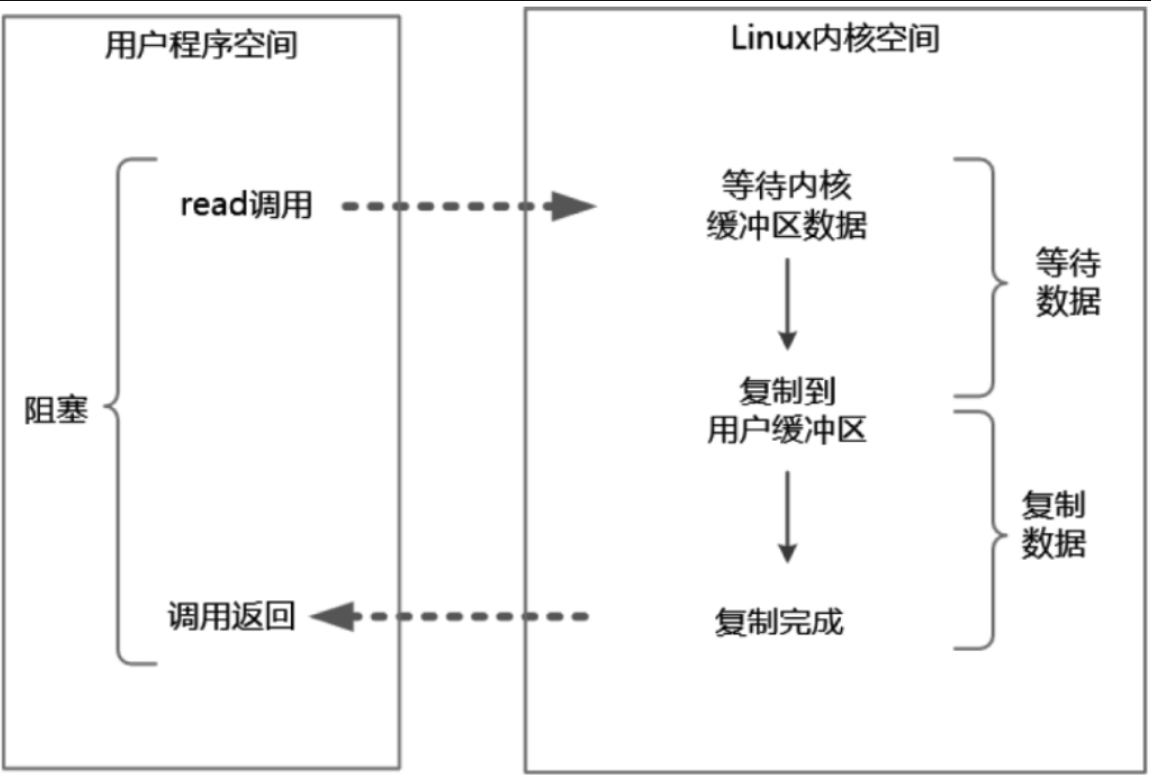
同步阻塞IO
在阻塞式IO模型中,从Java应用程序发起IO系统调用开始,一直到系统调用返回,这段时间内发起IO请求的Java进程(或者线程)是阻塞的。直到返回成功后,应用进程才能开始处理用户空间的缓冲区数据。过程如图所示:
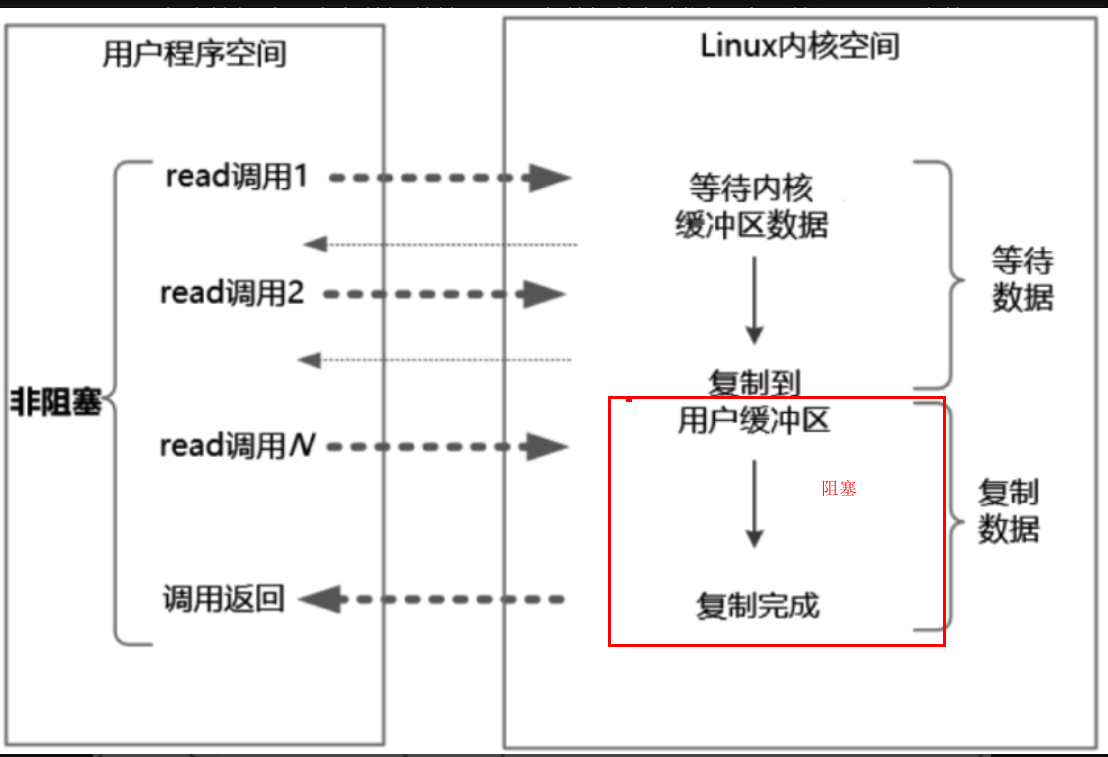
同步非阻塞IO(NIO)
在NIO模型中,应用程序一旦开始IO系统调用,就会出现以下两种情况:
在内核缓冲区中没有数据的情况下,系统调用会立即返回一个调用失败的信息。
在内核缓冲区中有数据的情况下,在数据的复制过程中系统调用是阻塞的,直到完成数据从内核缓冲区复制到用户缓冲区。复制完成后,系统调用返回成功,用户进程(或者线程)可以开始处理用户空间的缓冲区数据。
过程如下图所示:
同步非阻塞IO需要不停的轮询等待,为了解决这个问题,采用了IO多路复用模型,过程图如下:
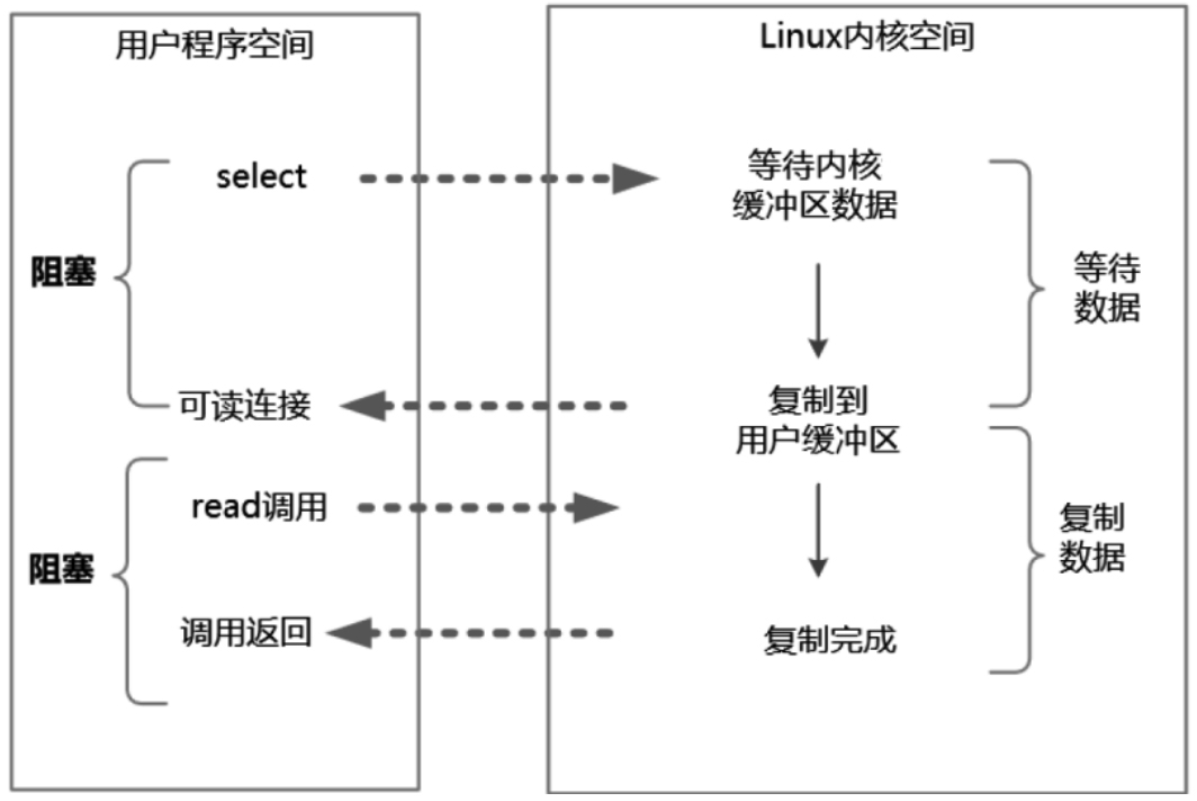
- 选择器注册。首先,将需要read操作的目标文件描述符(socket连接)提前注册到Linux的select/epoll选择器中,在Java中所对应的选择器类是Selector类。然后,开启整个IO多路复用模型的轮询流程。
- 就绪状态的轮询。通过选择器的查询方法,查询所有提前注册过的目标文件描述符(socket连接)的IO就绪状态。通过查询的系统调用,内核会返回一个就绪的socket列表。当任何一个注册过的socket中的数据准备好或者就绪了就说明内核缓冲区有数据了,内核将该socket加入就绪的列表中,并且返回就绪事件。
- 用户线程获得了就绪状态的列表后,根据其中的socket连接发起read系统调用,用户线程阻塞。内核开始复制数据,将数据从内核缓冲区复制到用户缓冲区。
- 复制完成后,内核返回结果,用户线程才会解除阻塞的状态,用户线程读取到了数据,继续执行。
IO多路复用模型的优点是一个选择器查询线程可以同时处理成千上万的网络连接,所以用户程序不必创建大量的线程,也不必维护这些线程,从而大大减少了系统的开销。与一个线程维护一个连接的阻塞IO模式相比,这一点是IO多路复用模型的最大优势。IO多路复用模型的缺点是,本质上select/epoll系统调用是阻塞式的,属于同步IO,需要在读写事件就绪后由系统调用本身负责读写,也就是说这个读写过程是阻塞的。要彻底地解除线程的阻塞,就必须使用异步IO模型。
异步IO
基本流程:用户线程通过系统调用向内核注册某个IO操作。内核在整个IO操作(包括数据准备、数据复制)完成后通知用户程序,用户执行后续的业务操作。