Elasticsearch基本概念
大约 4 分钟ElasticsearchElasticsearch
Elasticsearch是什么?
Elasticsearch是一个开源的分布式搜索和分析引擎,构建在Apache Lucene库之上。它提供了一个高性能、可扩展和分布式的存储和检索引擎,用于处理和分析大规模的实时数据。
Elasticsearch的设计目标是为了能够快速、准确地搜索和分析各种类型的数据,包括结构化、半结构化和非结构化数据。它支持全文搜索、地理空间搜索、结构化查询、聚合分析和实时数据处理。
ElasticSearch应用场景
Elasticsearch在许多不同的应用场景中被广泛使用。以下是一些常见的Elasticsearch应用场景:
- 实时日志分析:Elasticsearch可以接收和索引大量的实时日志数据,并提供强大的搜索和分析功能。它能够帮助你快速检索和分析日志,以便实时监控应用程序、故障排除和性能优化。
- 搜索引擎 :Elasticsearch可以作为搜索引擎使用,帮助用户在大规模的文档集合中进行快速、准确的全文搜索。它支持高亮显示、相关性排名和复杂的查询,使用户能够快速找到他们所需的信息。
- 地理空间数据分析:Elasticsearch具有对地理空间数据的强大支持,可以进行地理空间搜索、地理空间聚合和地理空间分析。这使得它在位置服务、地理信息系统(GIS)和地理空间分析应用中非常有用。
- 数据监控:Elasticsearch可以用于实时监控和分析各种类型的数据指标。你可以将时间序列数据存储在Elasticsearch中,并使用聚合功能计算指标的统计信息、趋势和警报。国内顶级开源APM Skywalking也是使用Elasticsearch存储监控数据。
Elasticsearch基本概念
- 索引(Index):索引是一种数据集合,它包含了一组具有相似特征的文档。每个文档都有一个唯一的标识符,称为文档ID。索引被用来存储、搜索和分析数据。
- 文档(Document):文档是Elasticsearch中的基本数据单元。它是一个包含了实际数据的JSON对象。每个文档都属于一个索引,并且在索引中通过其唯一的文档ID进行标识。
- 类型(Type):在早期的Elasticsearch版本中,一个索引可以包含多个类型,每个类型都有自己的映射和设置。从Elasticsearch 7.0版本开始,类型被弃用了,一个索引只能包含一个映射类型。目前,类型被视为内置的"_doc"类型。
- 映射(Mapping):映射定义了索引中每个字段的数据类型和其他属性。它描述了文档的结构和字段如何被索引和搜索。映射可以是显式定义的,也可以是隐式推断的。
- 节点(Node):节点是Elasticsearch集群中的单个服务器实例。每个节点都是一个独立的Elasticsearch实例,可以存储数据、处理请求,并参与集群的协调和管理。一个集群可以由多个节点组成。
- 集群(Cluster):集群是由一个或多个节点组成的集合。集群通过共享数据和负载均衡来提供高可用性和伸缩性。当你添加或删除节点时,集群会自动重新分配数据以保持均衡。
- gateway:代表Elasticsearch索引快照的存储方式,Elasticsearch默认优先将索引存放到内存中,当内存满时再将这些索引持久化存储至本地硬盘。gateway对索引快照进行存储,当这个Elasticsearch集群关闭再重新启动时就会从gateway中读取索引备份数据。Elasticsearch支持多种类型的gateway,有本地文件系统(默认)、分布式文件系统、Hadoop的HDFS。
- Transport:代表Elasticsearch内部节点或集群与客户端的交互方式,默认使用TCP协议进行交互。同时支持通过插件的方式集成,因此也可以使用HTTP协议(JSON格式)、thrift、memcached、zeroMQ等传输协议进行交互。
- 分片和副本(Shards and Replicas):为了支持大规模数据和高吞吐量,索引被分割成多个分片。每个分片是一个独立的索引部分,它可以被分配给不同的节点。副本是分片的复制品,用于提供数据的冗余和高可用性。
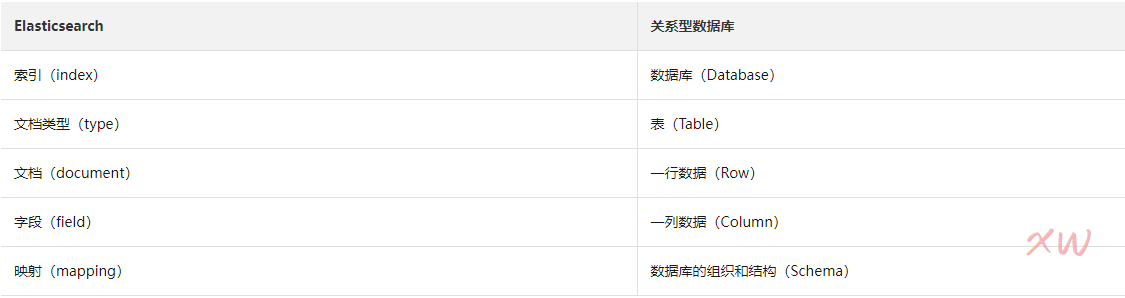
Elasticsearch与关系型数据库的映射关系如下表所示: