Elasticsearch性能优化
写入优化
在对es进行写入速度优化前,首先了解一下es内部文档的写入流程,大致流程图如下:
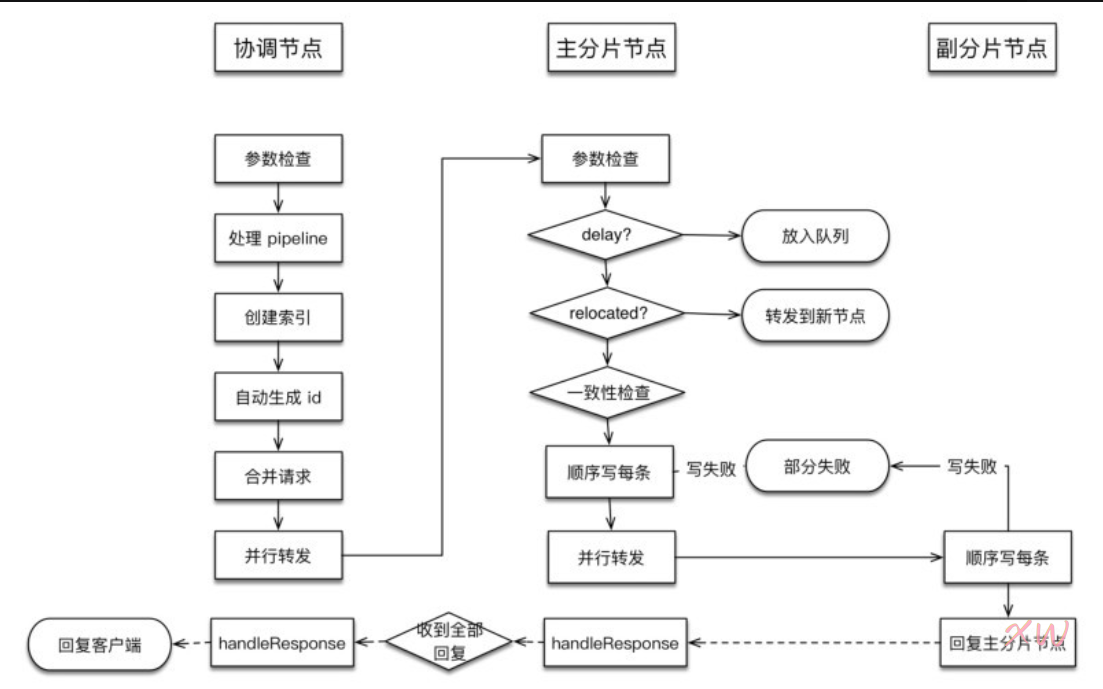
- 协调节点主要负责创建索引、转发请求到主分片节点、等待响应、返回客户端。
- 转发请求到主分片节点后,主节点执行写操作(先写Lucene,后写translog,根据translog刷盘策略刷盘),写成功后转发副本片执行写操作,等待响应。
- 给协调节点返回消息。
写入操作关键细化流程如下图所示:
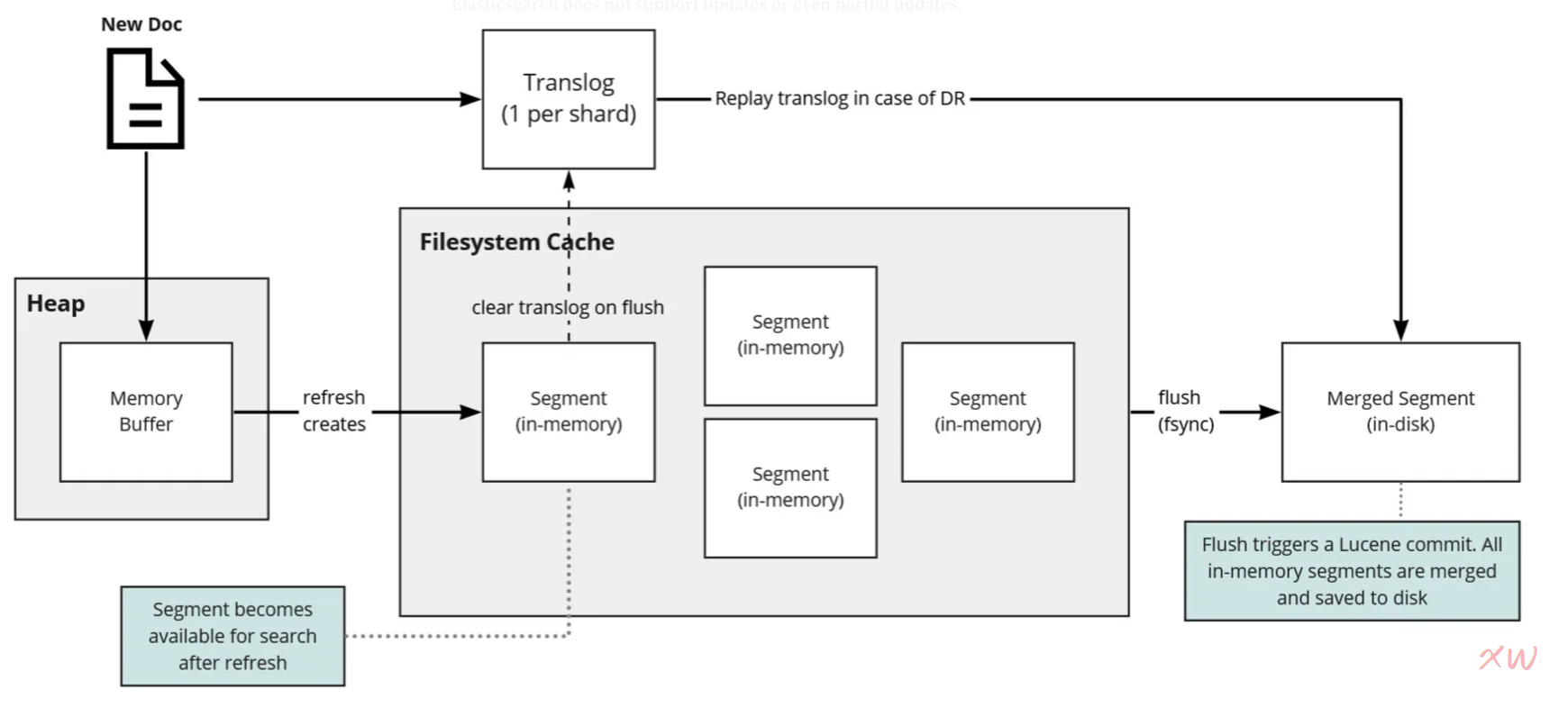
- 当发生写入操作时 ,会将文档写入内存缓冲区及事务日志(translog),事务日志(translog)是为了防止发生崩溃引发数据丢失问题
- 当刷新操作发生时,内存缓冲区中的所有文档将在内存中生成一个单独的Lucene段。执行刷新操作后该文档将能够被搜索到。
- 在某个时机,这些段都合并为一个段并保存到磁盘,并清除translog。
事务日志刷盘间隔
默认设置下,translog的持久化策略为:每个请求都flush,如果系统可以接受一定概率的数据丢失,调整translog持久化策略为周期性和一定大小的时候flush,具体配置如下:
index.translog.durability: async
request: 这是默认值,表示事务日志在每个写入请求成功响应后都会持久化到磁盘。这是最安全的选项,
因为它确保了写入操作的持久性,但会带来额外的写入延迟,因为每个写入请求都需要等待事务日志的写入完成。
async: 这个选项会将事务日志的持久化操作放在后台异步执行,不会阻塞写入请求的响应。
写入请求会立即返回,而事务日志的持久化操作则在后台异步执行。这样可以提高写入性能和响应速度,
但会增加一定的数据丢失风险,因为在事务日志持久化之前,数据仍然存在于内存中。
## 设置同步间隔,当index.translog.durability: async生效
index.translog.sync_interval: 120s
##超过这个大小会导致refresh操作,产生新的Lucene分段。默认值为512MB。
index.translog.flush_threshold_size: 1024mb
修改方式如下:
PUT /index_name/_settings
{
"index": {
"translog.sync_interval": "1s"
}
}
索引刷新间隔
默认情况下索引的refresh_interval为1秒,这意味着数据写1秒后就可以被搜索到,每次索引的refresh会产生一个新的Lucene段,这会导致频繁的segment merge行为,如果不需要这么高的搜索实时性,应该降低索引refresh周期。修改方式如下:
PUT /my-index-000001/_settings
{
"index": {
"refresh_interval": "10s"
}
}
indexing buffer(索引缓冲)
当文档被索引时,它们首先会被写入索引缓冲,而不是立即写入磁盘。索引缓冲会在内存中维护待索引文档的变动。当满足某些条件时,Elasticsearch会将索引缓冲中的文档批量写入磁盘,形成一个新的段(segment),从而提高写入性能。
相关配置如下:
index.memory.buffer_size:这个配置选项用于设置索引缓冲的总大小。默认情况下,它是自动计算的,根据可用的堆内存大小进行分配。
你可以手动指定一个较小或较大的值来调整索引缓冲的大小。较大的缓冲区大小可以提高写入性能,但会占用更多的内存资源。默认为整个堆空间的10%
##缓冲池最小值
indices.memory.min_index_buffer_size
##最大无限制
indices.memory.min_index_buffer_size
批量写
批量写比一个索引请求只写单个文档的效率高得多,但是要注意bulk请求的整体字节数不要太大,太大的请求可能会给集群带来内存压力。
可使用GET /_cat/thread_pool?v命令节点线程池情况
节点间任务均衡
数据写入客户端应该把bulk请求轮询发送到各个节点。
尽量不频繁更新数据
尽量不要频繁更新数据,因为es更新数据会将原来的数据删除并创建新的记录。
自动生成id
写入doc时如果外部指定了id,则ES会先尝试读取原来doc的版本号,以判断是否需要更新。这会涉及一次读取磁盘的操作,通过自动生成doc ID可以避免这个环节。
禁用副本(看使用场景❗)
如果可以在批量索引作业期间禁用副本,还可以大大提高索引速度。当为文档建立索引时,它将被每个副本复制,这会大大影响性能。另一方面,如果在批量作业之前禁用副本,然后才启用副本,则新信息将以序列化的二进制格式复制,而无需分析或合并段。
查询优化
文件缓存
Linux会自动使用空闲内存缓存文件。Elastic建议运行Elasticsearch的机器至少有一半的内存可用于文件系统缓存。确保不要将ES HEAP SIZE设置为超过机器内存的50%,这样剩余的内存就可以用于文件系统缓存。应该避免使用超过32GB的HEAP,因为它将开始使用未压缩的指针,这将影响性能并使用双倍的内存。线上应该禁用swap。
使用更快的硬件
写入性能对CPU的性能更敏感,而搜索性能在一般情况下更多的是在于I/O能力,优先使用SSD这种较快的存储设备。
为只读索引执行force-merge
为不再更新的只读索引执行force merge,将Lucene索引合并为单个分段,可以提升查询速度。当一个Lucene索引存在多个分段时,每个分段会单独执行搜索再将结果合并,将只读索引强制合并为一个Lucene分段不仅可以优化搜索过程,对索引恢复速度也有好处。
合理建模
应该对文档进行建模,使搜索时间操作尽可能便宜。特别是,应该避免join、嵌套会使查询速度慢几倍,父子关系会使查询速度慢数百倍。因此,如果可以通过对文档进行非规范化来解决相同的问题,那么可以预期会有显著的速度提高。
尽量搜索更少的字段
查询字符串或多匹配查询针对的字段越多,速度就越慢。提高多个字段的搜索速度的一种常用技术是在索引时将它们的值复制到单个字段中,然后在搜索时使用该字段。这可以通过映射的copy_to指令自动完成。
尽量避免使用脚本
尽量避免使用基于脚本的排序、聚合脚本和脚本评分查询。
预热全局序号
全局序号是一种数据结构,用于在keyword字段上运行terms聚合。它用一个数值来代表字段中的字符串值,然后为每一数值分配一个 bucket。这需要一个对global ordinals 和 bucket的构建过程。默认情况下,它们被延迟构建,因为ES不知道哪些字段将用于 terms聚合,哪些字段不会。可以通过配置映射在刷新(refresh)时告诉ES预先加载全局序数,使用方式如下:
PUT index
{
"mappings": {
"properties": {
"foo": {
"type": "keyword",
"eager_global_ordinals": true
}
}
}
}
预热文件系统cache
如果ES主机重启,则文件系统缓存将为空,此时搜索会比较慢。可以使用index.store.preload设置,通过指定文件扩展名,显式地告诉操作系统应该将哪些文件加载到内存中,使用设置如下:
PUT /my-index-000001/_settings
{
"index": {
"store.preload": ["nvd", "dvd"]
}
}