Elasticsearch高级查询
生成测试数据
执行以下命令,生成测试数据。
POST /account/_bulk
{"index":{"_id":"1"}}
{"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"}
{"index":{"_id":"6"}}
{"account_number":6,"balance":5686,"firstname":"Hattie","lastname":"Bond","age":36,"gender":"M","address":"671 Bristol Street","employer":"Netagy","email":"hattiebond@netagy.com","city":"Dante","state":"TN"}
{"index":{"_id":"13"}}
{"account_number":13,"balance":32838,"firstname":"Nanette","lastname":"Bates","age":28,"gender":"F","address":"789 Madison Street","employer":"Quility","email":"nanettebates@quility.com","city":"Nogal","state":"VA"}
{"index":{"_id":"18"}}
{"account_number":18,"balance":4180,"firstname":"Dale","lastname":"Adams","age":33,"gender":"M","address":"467 Hutchinson Court","employer":"Boink","email":"daleadams@boink.com","city":"Orick","state":"MD"}
{"index":{"_id":"20"}}
{"account_number":20,"balance":16418,"firstname":"Elinor","lastname":"Ratliff","age":36,"gender":"M","address":"282 Kings Place","employer":"Scentric","email":"elinorratliff@scentric.com","city":"Ribera","state":"WA"}
{"index":{"_id":"25"}}
{"account_number":25,"balance":40540,"firstname":"Virginia","lastname":"Ayala","age":39,"gender":"F","address":"171 Putnam Avenue","employer":"Filodyne","email":"virginiaayala@filodyne.com","city":"Nicholson","state":"PA"}
{"index":{"_id":"32"}}
{"account_number":32,"balance":48086,"firstname":"Dillard","lastname":"Mcpherson","age":34,"gender":"F","address":"702 Quentin Street","employer":"Quailcom","email":"dillardmcpherson@quailcom.com","city":"Veguita","state":"IN"}
{"index":{"_id":"37"}}
{"account_number":37,"balance":18612,"firstname":"Mcgee","lastname":"Mooney","age":39,"gender":"M","address":"826 Fillmore Place","employer":"Reversus","email":"mcgeemooney@reversus.com","city":"Tooleville","state":"OK"}
DSL查询操作
term查询
Term查询是Elasticsearch中的一种查询类型,用于精确匹配某个字段的值。它在查询过程中不会对搜索词进行分析,而是直接按照给定的词项进行匹配。示例如下:
GET /account/_search
{
"query": {
"term": {
"firstname.keyword": {
"value": "Amber"
}
}
}
}
match查询
示例 如下:
GET /account/_search
{
"query": {
"match": {
"firstname": "Amber"
}
}
}
注
从示例看term与match作用差不多,都是匹配某个字段的值,但是它们在查询方式和匹配规则上有一些区别:
- 分析与不分析:Match查询会对搜索词进行分析,而Term查询则不会。Match查询会将搜索词进行分词处理,生成词项后再进行匹配。Term查询直接按照给定的搜索词进行匹配,不进行分析。
- 匹配方式:Match查询使用的是全文匹配,它会将搜索词与字段中的文本进行匹配。它可以处理多词项、模糊匹配和相似度评分等。Term查询则是精确匹配,只会匹配完全相同的词项。
- 字段类型:Match查询可以用于任何字段类型,而Term查询主要用于精确匹配字段,如关键字字段或不需要分析的字段。对于文本字段,建议使用Match查询,而对于关键字字段或精确匹配要求较高的字段,可以使用Term查询。
- 性能:由于Match查询会进行分析和评分计算,它的查询速度可能比Term查询慢一些。Term查询直接按照给定的词项进行匹配,通常更快速。
总结起来,Match查询适用于全文搜索和处理自然语言查询,能够处理分词、模糊匹配和评分等功能。而Term查询适用于精确匹配,不进行分析,性能更高。
match_phrase
Match Phrase查询会将搜索词作为一个短语进行匹配,保持搜索词中的单词顺序,并且要求文档中的字段包含完全相同的短语。它不会对搜索词进行分词处理,而是将整个搜索词作为一个单元进行匹配。
GET /account/_search
{
"query": {
"match_phrase": {
"address":{
"query": "880"
}
}
}
}
默认必须保持顺序才能 够查询出来,如果需要乱序,添加slop参数:
GET /account/_search
{
"query": {
"match_phrase": {
"address":{
"query": "Holmes 880"
, "slop": 2
}
}
}
}
wildcard查询
wildcard用于基于通配符模式匹配字段值。它可以在查询时使用通配符字符(*和?)来代替部分或全部字符,以便进行模糊匹配。
Wildcard查询使用通配符字符来匹配字段值,其中:
*表示零个或多个字符。?表示一个单个字符。
示例如下:
GET /account/_search
{
"query": {
"wildcard": {
"firstname.keyword":"Am*"
}
}
}
Range查询
范围查询,示例如下:
GET /account/_search
{
"query": {
"range": {
"age": {
"gte": 10,
"lte": 40
}
}
}
}
Fuzzy查询
Fuzzy查询是Elasticsearch中的一种查询类型,用于模糊匹配字段值。它可以在查询时允许一定程度的编辑距离(即字符的插入、删除或替换)来匹配字段值,从而实现近似匹配。Fuzzy查询通过计算查询词与文档中字段值之间的编辑距离来确定匹配程度。编辑距离表示将一个字符串转换为另一个字符串所需的最少编辑操作次数。这些操作可以是插入、删除或替换字符。示例如下:
GET /account/_search
{
"query": {
"fuzzy": {
"firstname.keyword": {
"value":"Ambxr"
}
}
}
}
Bool查询
Bool查询是Elasticsearch中的一种复合查询,用于组合多个查询条件。它通过逻辑运算符(AND、OR、NOT)以及子查询来构建复杂的查询逻辑。
Bool查询由以下四个主要组件构成:
- Must查询:所有Must查询条件都必须满足才能匹配文档。它们使用逻辑运算符AND组合在一起。
- Should查询:Should查询条件中的任意一个满足即可匹配文档。它们使用逻辑运算符OR组合在一起。可以指定Should查询条件的最小匹配数量(
minimum_should_match),以控制匹配的灵活性。 - Must Not查询:Must Not查询条件必须不满足才能匹配文档。它们使用逻辑运算符NOT组合在一起。
- filter查询:必须出现在⽂档中,但是不打分
示例如下:
GET /account/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"firstname.keyword": {
"value": "Dillard"
}
}
}
],
"should": [
{"range": {
"balance": {
"gte": 10,
"lte": 22222220
}
}}
],
"must_not": [
{"term": {
"state.keyword": {
"value": "MD"
}
}}
],
"filter": [
{
"term": {
"gender.keyword": "F"
}
}
]
}
}
}
排序查询
在Elasticsearch中,可以使用排序查询(Sort Query)对搜索结果进行排序。排序查询允许你指定一个或多个字段作为排序依据,并指定排序的方式(升序或降序)。
示例如下:
## 根据年纪升序排序,年纪一样按照余额逆序排序
GET /account/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "asc"
}
},
{
"balance": {
"order": "desc"
}
}
]
}
聚合查询(指标聚合)
在Elasticsearch中,聚合查询(Aggregation Query)用于对搜索结果进行统计分析和聚合操作,以便获取关于数据的汇总信息。聚合查询能够提供诸如计数、求和、平均值、最大值、最小值、分组等统计结果。
示例:
## 求平均余额
GET /account/_search
{
"query": {
"match_all": {}
},
"aggs": {
"avage-balance": {
"avg": {
"field": "balance"
}
}
}
}
常用操作如下:
max min sum avg
value_count:统计⾮空字段的⽂档数
Cardinality 值去重计数
stats:统计count max min avg sum 5个值
Extended stats:⽐stats多4个统计结果: 平⽅和、⽅差、标准差、平均值加/减两个标准差的区间
Percentiles:占⽐百分位对应的值统计,默认返回[ 1, 5, 25, 50, 75, 95, 99 ]分位上的值,示例如下:
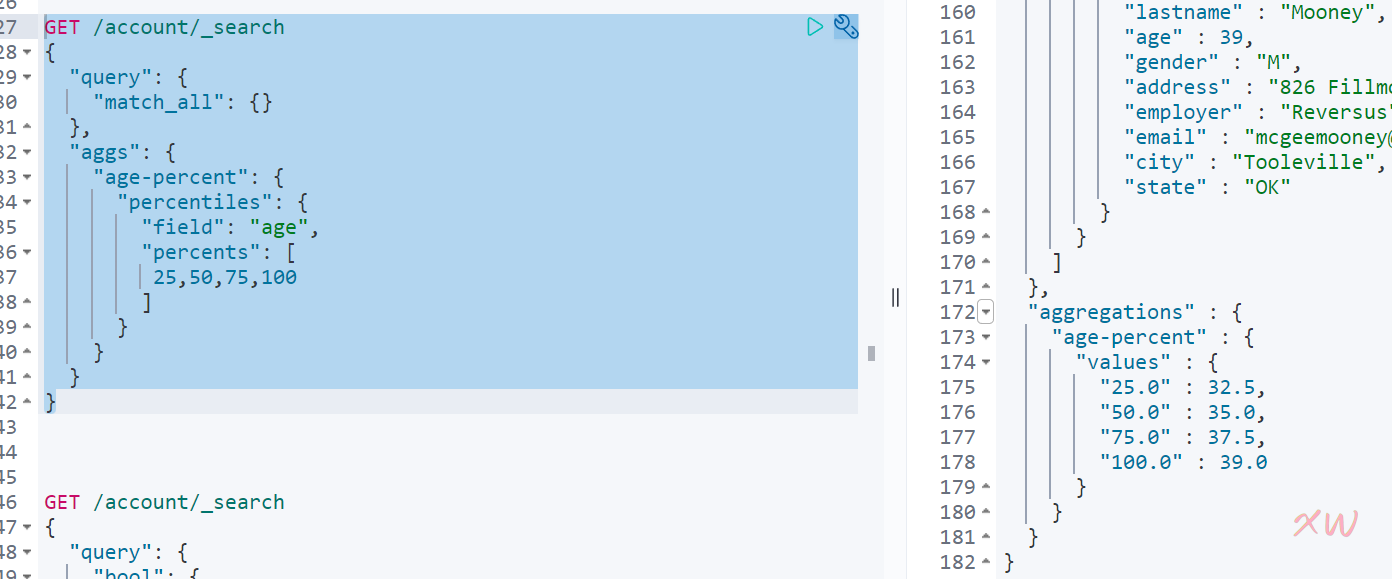
表示有25%的值小于32.5,50%的值小于35.....
聚合查询(桶聚合)
桶聚合(Bucket Aggregation)是Elasticsearch中的一种聚合类型,用于按照指定的条件将文档分组到不同的桶中,然后对每个桶内的文档进行统计分析。桶聚合可用于对数据进行分组、分段、分级等操作,以获取更细粒度的统计结果。
桶聚合有多种类型,常用的包括:
- Terms聚合:按照指定字段的值进行分组,并返回每个分组的文档数量。可以获取分组的Top N结果。
- Date Histogram聚合:按照日期字段进行分组,并将时间段划分为固定间隔的桶,用于时间序列数据的分析。
- Range聚合:根据指定的范围条件将文档分配到不同的桶中,用于对数值型字段进行范围分组。
- Nested聚合:对嵌套文档进行分组和统计分析。
示例如下:
## 根据年纪进行分组
GET /account/_search
{
"query": {
"match_all": {}
},
"aggs": {
"ages": {
"terms": {
"field": "age",
"size": 10
}
}
}
}
SQL查询
在Elasticsearch中,可以使用SQL查询来执行SQL语句,以便对索引中的数据进行查询和分析。Elasticsearch提供了SQL查询的功能,可以使用SQL语法来编写查询语句,类似于传统的关系型数据库。
示例:
POST /_sql?format=json
{
"query": """
SELECT * FROM "account"
"""
}
提示
SQL查询在某些情况下可能会受到性能限制,尤其是在大规模数据集上进行复杂查询时。导致性能下降的原因有如下几个:
- 数据模型不匹配: Elasticsearch是一个分布式文档型数据库,其数据模型与传统的关系型数据库不同。关系型数据库通常使用规范化模型,而Elasticsearch更适合使用冗余和扁平化的数据模型。如果将传统的关系型数据库的查询直接转换为SQL查询,并没有充分利用Elasticsearch的数据模型和查询优化功能,可能导致性能下降。
- 全文搜索和分词: Elasticsearch在文本搜索和分词方面表现出色,可以对文本字段进行全文搜索和分词处理。然而,对于复杂的文本查询,特别是涉及模糊搜索、通配符查询和近似匹配等操作,使用SQL查询可能无法充分发挥Elasticsearch的全文搜索功能,从而影响性能。