Mysql事务浅析
[TOC]
概述
索引是并发控制的基本单位,它是一个操作序列,要么这些操作都执行成功,要么都不执行。事务的四大特性ACID:
原子性(Atomicity):原子性指的是整个数据库的事务是一个不可分割的工作单位,每一个都应该是一个原子操作。
当我们执行一个事务的时候,如果一系列的操作中,有一个操作失败了,那么,需要将这一个事务中的所有操作恢复到执行事务之前的状态,这就是事务的原子性
一致性(Consistency):一致性是指事务将数据库从一种状态转变为下一种一致性的状态,也就是说在事务执行前后,这两种状态应该是一样的,也就是数据库的完整性约束不会被破坏,另外,需要注意的是一致性是不关注中间状态的
隔离性(Isolation):MySQL数据库中可以同时启动很多的事务,但是,事务和事务之间他们是相互分离的,也就是互不影响的,这就是事务的隔离性。
持久性(Durability):事务的持久性是指事务一旦提交,就是永久的了,就是发生问题,数据库也是可以恢复的。因此,持久性保证事务的高可靠性
事务隔离级别
read uncommitted(读取未提交数据):即便是事务没有commit,但是其他连接仍然能读到未提交的数据,这是所有隔离级别中最低的一种
read committed(可以读取其他事务提交的数据):当前会话只能读取到其他事务提交的数据,未提交的数据读不到
repeatable read(可重读)---MySQL默认的隔离级别:当前会话可以重复读,就是每次读取的结果集都相同,而不管其他事务有没有提交
serializable(串行化):其他会话对该表的写操作将被挂起。可以看到,这是隔离级别中最严格的,但是这样做势必对性能造成影响
脏读幻读不可重复读
脏读:所谓脏读是指一个事务中访问到了另外一个事务未提交的数据

幻读:一个事务读取2次,得到的记录条数不一致

不可重复读:一个事务读取同一条记录2次,得到的结果不一致

Mysql数据执行过程

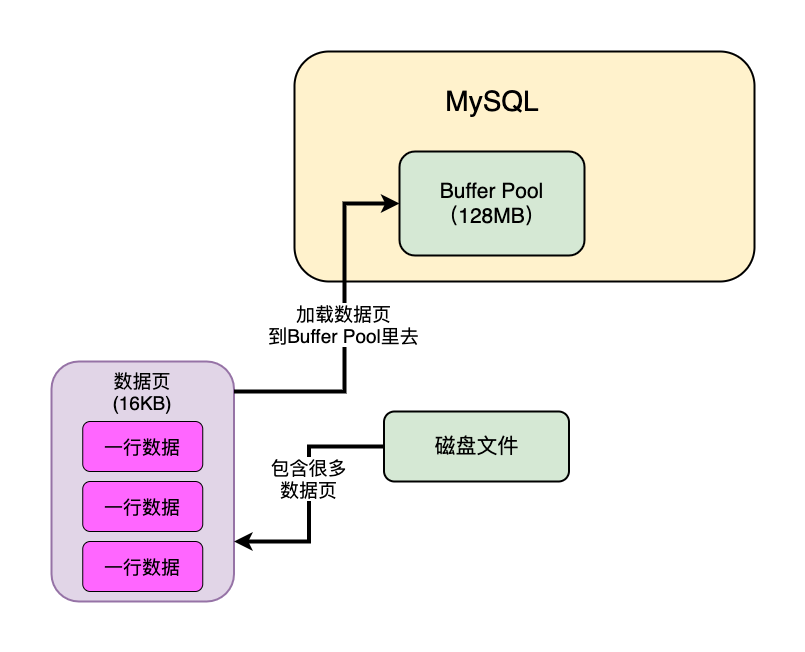
- Buffer Pool从磁盘加载数据,缓存到内存。
- 当有数据更新操作时,先将旧的数据写入undo日志,用于失败的情况下回滚。
- 更新Buffer Pool缓存中的数据,io线程异步将数据刷入磁盘。
- 在事务提交前,也会写入redo log进行持久化,因为更新不会直接落盘,只会更新缓存中的数据,这种情况下宕机会造成数据丢失。
Buffer Pool
Buffer Pool就是数据库的一个内存组件,缓存了磁盘上的真实数据,我们的系统对数据库执行的增删改操作,其实主要就是对这个内存数据结构中的缓存数据执行的
查看缓存区大小命令:
show global variables like 'innodb_buffer_pool_size';
缓存更新策略采用LRU算法实现。
undo log
undo log记录事务变更前的状态。操作数据之前,先将数据备份到undo log,然后进行数据修改,如果出现错误或用户执行了rollback语句,则系统就可以利用undo log中的备份数据恢复到事务开始之前的状态。
redo log
redo log 记录事务变更后的状态。在事务提交前,只要将redo log持久化即可,数据在内存中变更。当系统崩溃时,虽然数据没有落盘,但是redo log已持久化,系统可以根据redo Log的内容,将所有数据恢复到最新的状态。
redo log的同步机制:
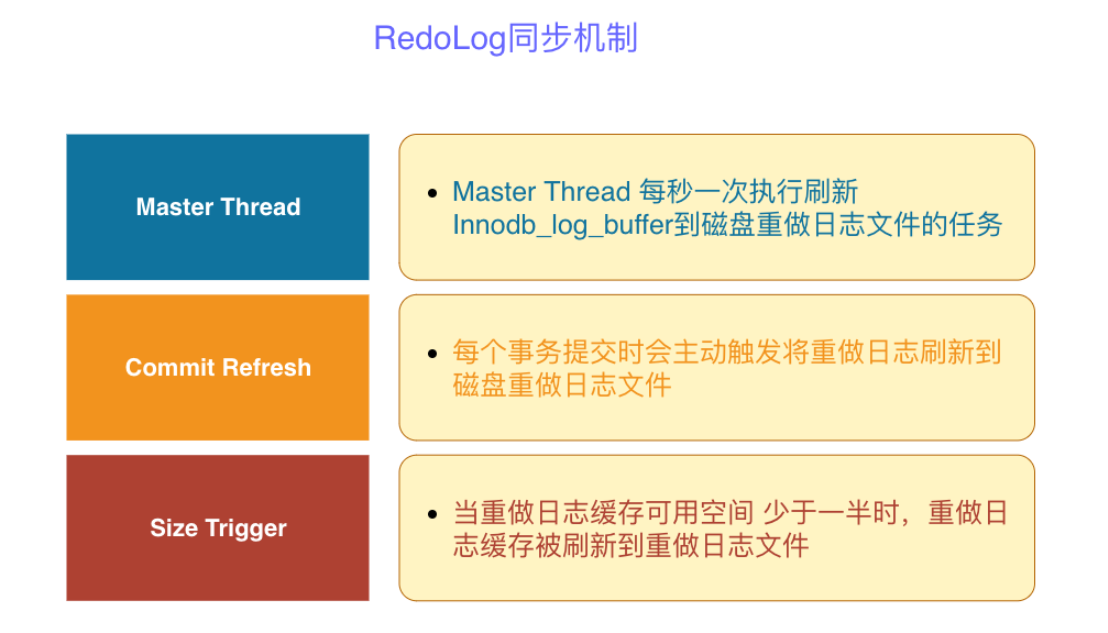
- **checkpoint:**随着时间的积累,redo Log会变的很大很大。如果每次都从第一条记录开始恢复,恢复的过程就会很慢。为了减少恢复的时间,就引入了checkpoint机制。定期将databuffer的内容刷新到磁盘datafile内,然后清除checkpoint之前的redo log。
MVCC结构
- InnoDB Multi-Versionning-InnoDB`是多版本存储引擎:它保留有关已更改行的旧版本的信息,以支持诸如并发和rollback的事务功能。此信息以称为rollback segment的数据结构存储在 table 空间中
- 实现原理:
InnoDB向存储在数据库中的每一行添加两个关键字段:DATA_TRX_ID和DATA_ROLL_PTR- 6字节的DATA_TRX_ID 标记了最新更新这条行记录的transaction id,每处理一个事务,其值自动+1
- DATA_ROLL_PTR则表示指向该行回滚段的指针,该行上所有旧的版本,在undo中都通过链表的形式组织,而该值,正式指向undo中该行的历史记录链表

MVCC的作用:
- 每行数据都存在一个版本,每次数据更新时都更新该版本
- 修改时Copy出当前版本随意修改,各个事务之间无干扰
- 把修改前的数据存放于undo log,通过回滚指针与主数据关联
- 修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
Read View:
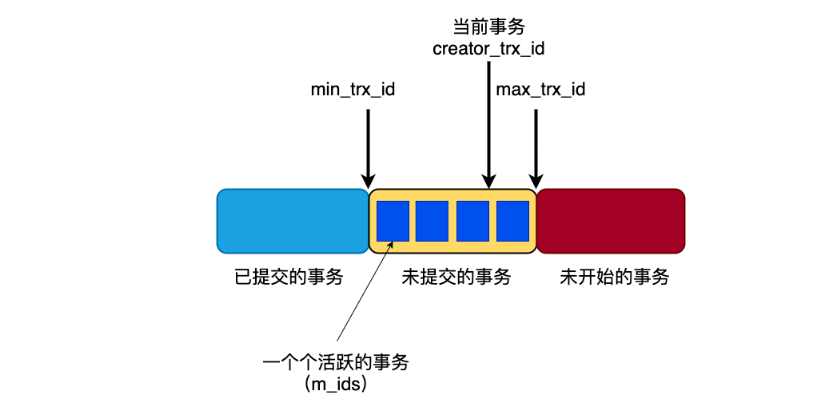
定义:ReadView是一个数据结构,在SQL开始的时候被创建。这个数据结构中包含了3个主要的成员:ReadView{low_trx_id, up_trx_id, trx_ids},在并发情况下,一个事务在启动时,trx_sys链表中存在部分还未提交的事务,那么哪些改变对当前事务是可见的,哪些又是不可见的,这个需要通过ReadView来进行判定
low_trx_id表示该SQL启动时,当前事务链表中最大的事务id编号,也就是最近创建的除自身以外最大事务编号;
up_trx_id表示该SQL启动时,当前事务链表中最小的事务id编号,也就是当前系统中创建最早但还未提交的事务;
trx_ids表示所有事务链表中事务的id集合 s1: insert into user(1,"Daniel") commit; s2: select * from user where id=1;
ReadView读取区别:
- READ COMMITTED —— 每次读取数据前都生成一个ReadView
- REPEATABLE READ —— 在第一次读取数据时生成一个ReadView
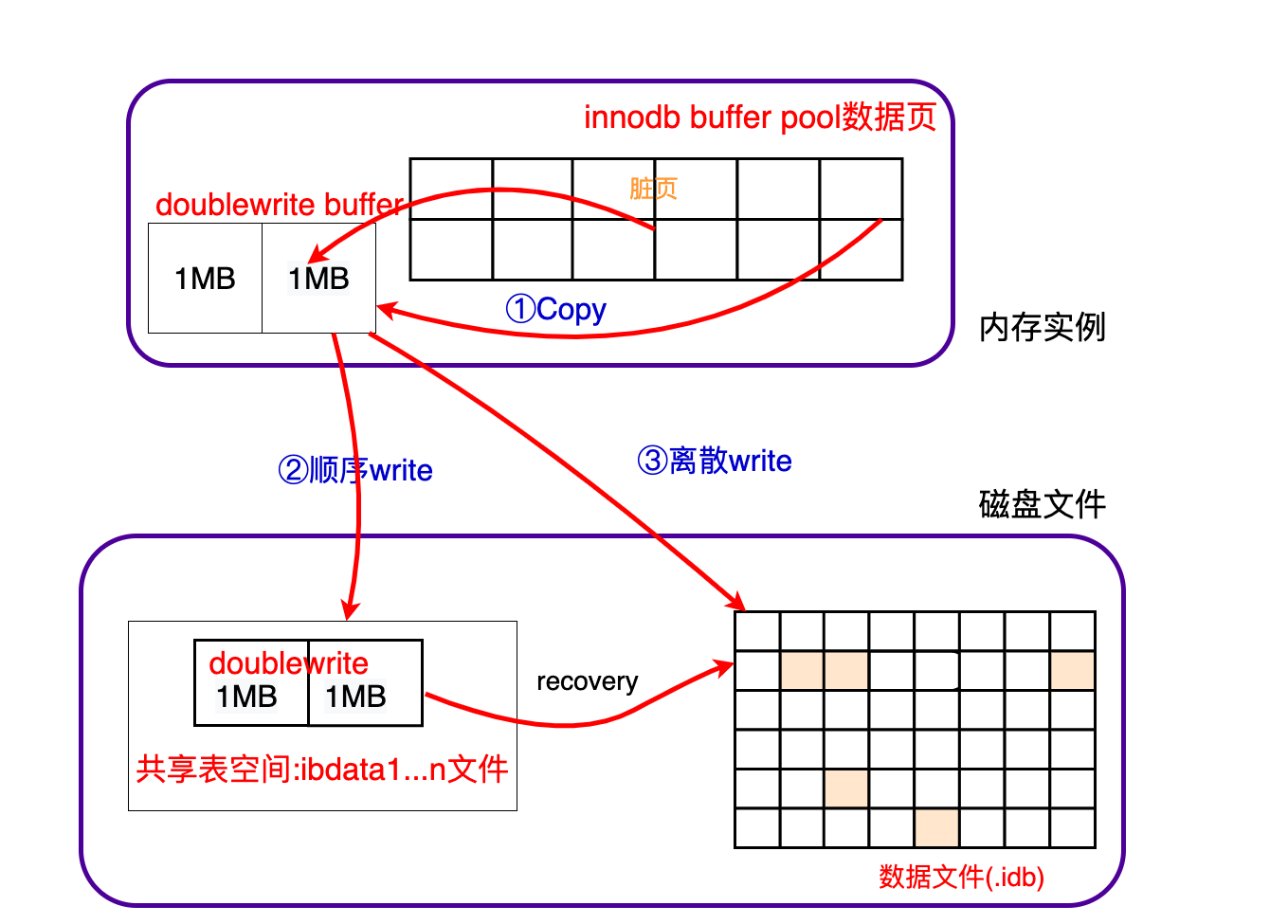
InnoDB doublewrite缓冲区
双重写入缓冲区,
InnoDB使用一种称为 doublewrite 的文件刷新技术。在将 页 写入 数据文件 之前,InnoDB首先将它们写入称为 doublewrite 缓冲区的存储区域作用:提高innodb的可靠性,用来解决部分写失败(partial page write页断裂)。在页面写入过程中发生 os,存储子系统或mysqld进程崩溃,则
InnoDB随后可以在“崩溃恢复”期间从 doublewrite 缓冲区中找到该页面的良好副本。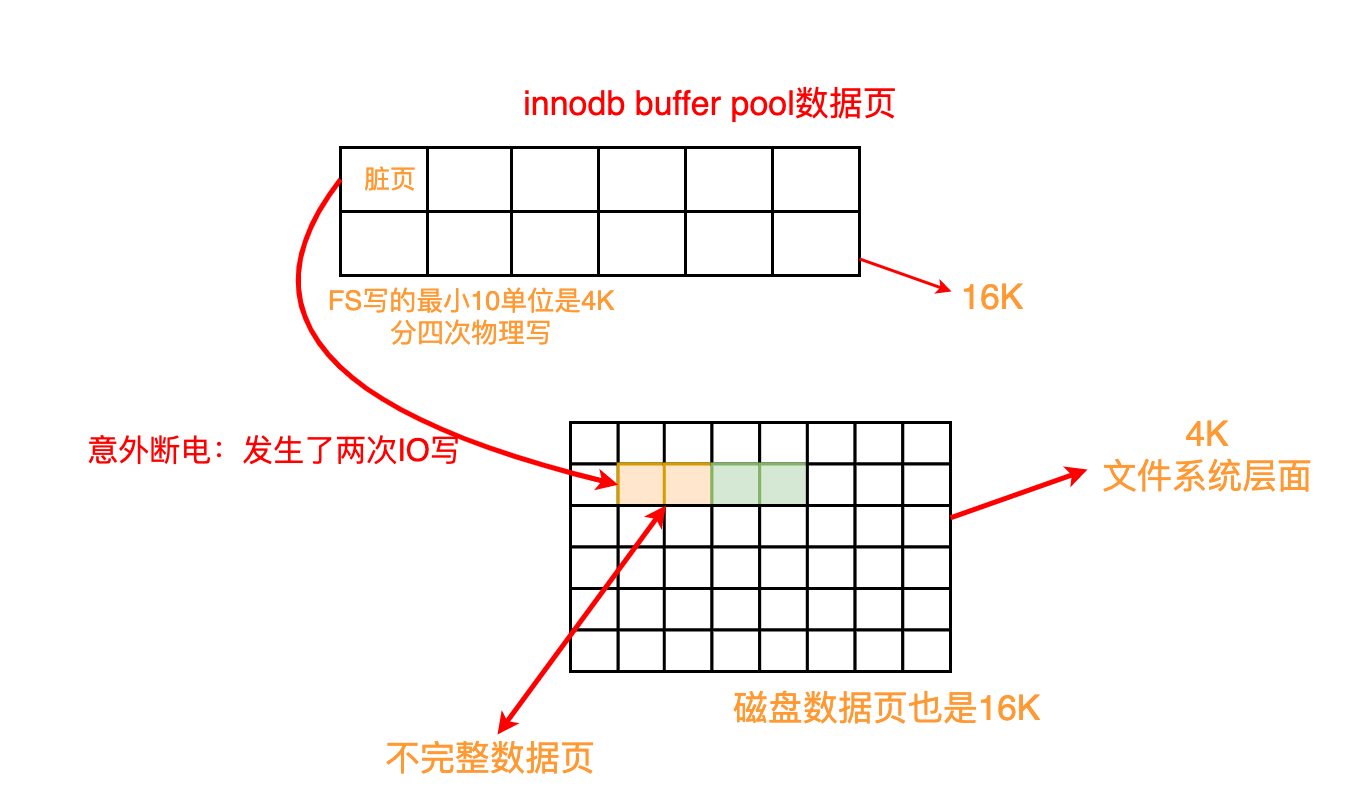
说明:buffer pool以页来存储数据,系统每次fsync() 调用是4k,一页是16K的数据,那么需要进行4次IO操作,如果发生了两次IO写时系统断电,那么磁盘数据文件这个数据页就是不完整的,是一个坏掉的数据页。redo只能加上旧的日志、校检完整的数据页恢复一个脏块,不能修复坏掉的数据页,所以这个数据就丢失了,可能造成数据不一致,所以需要double write。简单来说,double write是为了保证数据的完整性。
doublewrite工作机制
带来的问题:
- double write是一个buffer, 但其实它是开在物理文件上的一个buffer, 其实也就是file, 所以它会导致系统有更多的fsync操作, 而硬盘的fsync性能是很慢的, 所以它会降低mysql的整体性能。
- doublewrite buffer写入磁盘共享表空间这个过程是连续存储,是顺序写,性能非常高,(约占写的%10),牺牲一点写性能来保证数据页的完整还是很有必要的。
配置doublewrite
show variables like '%double%';