ShardingJdbc分库分表
常见分库分表中间件
业界常见分库分表中间件
- Cobar(已经被淘汰没使用了)
- TDDL
- 淘宝根据自己的业务特点开发了 TDDL (Taobao Distributed Data Layer)
- 基于JDBC规范,没有server,以client-jar的形式存在,引入项目即可使用
- 开源功能比较少,阿里内部使用为主
- Mycat
- 地址 http://www.mycat.org.cn/
- Java语言编写的MySQL数据库网络协议的开源中间件,前身 Cobar
- 遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理
- 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server 伪装成一个 MySQL 数据库
- 和ShardingShere下的Sharding-Proxy作用类似,需要单独部署
ShardingSphere 下的Sharding-JDBC
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈它由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar 3个独立产品组合
Sharding-JDBC
- 基于jdbc驱动,不用额外的proxy,支持任意实现 JDBC 规范的数据库
- 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖
- 可理解为加强版的 JDBC 驱动,兼容 JDBC 和各类 ORM 框架
ShardingSphere-JDBC将自己定义为一个轻量级Java框架,它在Java JDBC层提供额外的服务。由于客户端直接连接到数据库,它以jar的形式提供服务,不需要额外的部署和依赖。它可以被认为是一个增强的JDBC驱动程序,它完全兼容JDBC和各种ORM框架。架构图如下所示:
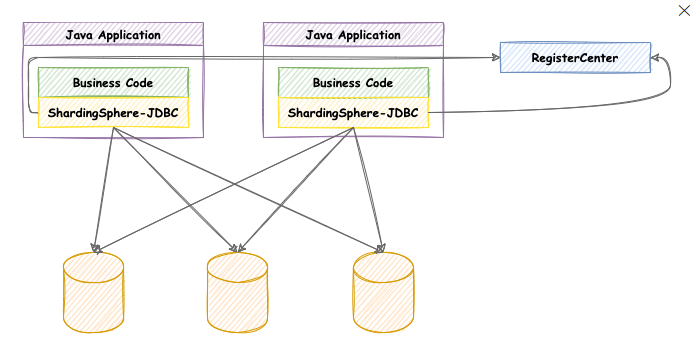
Mycat和ShardingJdbc区别:
- 两者设计理念相同,主流程都是SQL解析-->SQL路由-->SQL改写-->结果归并
- sharding-jdbc
- 基于jdbc驱动,不用额外的proxy,在本地应用层重写Jdbc原生的方法,实现数据库分片形式
- 是基于 JDBC 接口的扩展,是以 jar 包的形式提供轻量级服务的,性能高
- 代码有侵入性
- Mycat
- 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server 伪装成一个 MySQL 数据库
- 客户端所有的jdbc请求都必须要先交给MyCat,再有MyCat转发到具体的真实服务器
- 缺点是效率偏低,中间包装了一层
- 代码无侵入性
分库分表常见策略
range划分
方案1:根据自增ID范围去划分,案例如下:
- 1~1000000是table_1
- 1000000~2000000为table_2
- 。。。。
优点:
- id是自增长,可以无限增长
- 扩容不用迁移数据,容易维护
缺点:
- 数据倾斜严重,热点数据过于集中,部分节点有瓶颈
Hash取模
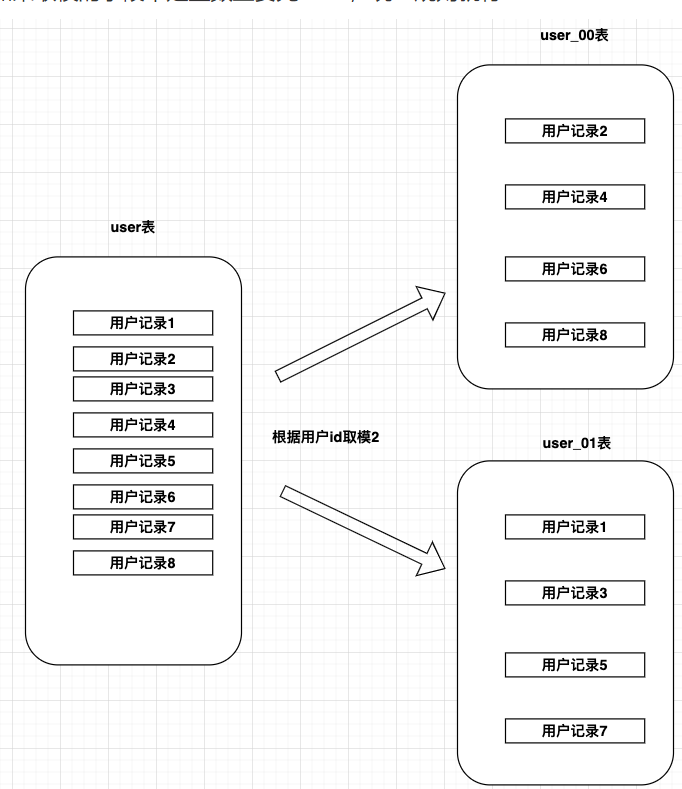
- 优点
- 保证数据较均匀的分散落在不同的库、表中,可以有效的避免热点数据集中问题,
- 缺点
- 扩容不是很方便,需要数据迁移
分库分表的优点及缺点
优点
- 解决数据库瓶颈(连接数限制,默认连接数为100,最大16384、单表海量数据查询性能问题、单台数据库并发访问压力)
- 解决系统瓶颈(磁盘读写IO瓶颈、网络IO瓶颈、CPU瓶颈)
缺点
- 跨节点数据库Join关联查询和多维度查询复杂
- 不同维度查看数据,利用的partitionKey是不一样的
- 分布式事务问题
- 执行的SQL排序、翻页、函数计算问题
- 数据库全局主键重复问题
- 二次扩容问题
- 分库分表技术选型问题
ShardingJdbc使用
分片策略
行表达式分片策略 InlineShardingStrategy
- 只支持【单分片键】使用Groovy的表达式,提供对SQL语句中的 =和IN 的分片操作支持
- 可以通过简单的配置使用,无需自定义分片算法,从而避免繁琐的Java代码开发
标准分片策略StandardShardingStrategy
- 只支持【单分片键】,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法
- PreciseShardingAlgorithm 精准分片 是必选的,用于处理=和IN的分片
- RangeShardingAlgorithm 范围分配 是可选的,用于处理BETWEEN AND分片
- 如果不配置RangeShardingAlgorithm,如果SQL中用了BETWEEN AND语法,则将按照全库路由处理,性能下降
复合分片策略ComplexShardingStrategy
- 支持【多分片键】,多分片键之间的关系复杂,由开发者自己实现,提供最大的灵活度
- 提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持
Hint分片策略HintShardingStrategy
这种分片策略无需配置分片健,分片健值也不再从 SQL中解析,外部手动指定分片健或分片库,让 SQL在指定的分库、分表中执行
用于处理使用Hint行分片的场景,通过Hint而非SQL解析的方式分片的策略
Hint策略会绕过SQL解析的,对于这些比较复杂的需要分片的查询,Hint分片策略性能可能会更好
不分片策略 NoneShardingStrategy
行表达式分片策略 InlineShardingStrategy
具体代码请查看完整项目,这里只贴关键配置
新建shop_order_0数据库,添加表product_order_0和product_order_1,生成Sql如下:
CREATE TABLE `product_order_1` (
`id` bigint NOT NULL AUTO_INCREMENT,
`out_trade_no` varchar(64) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '订单唯一标识',
`state` varchar(11) COLLATE utf8mb4_bin DEFAULT NULL COMMENT 'NEW 未支付订单,PAY已经支付订单,CANCEL超时取消订单',
`create_time` datetime DEFAULT NULL COMMENT '订单生成时间',
`pay_amount` decimal(16,2) DEFAULT NULL COMMENT '订单实际支付价格',
`nickname` varchar(64) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '昵称',
`user_id` bigint DEFAULT NULL COMMENT '用户id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
CREATE TABLE `product_order_0` (
`id` bigint NOT NULL AUTO_INCREMENT,
`out_trade_no` varchar(64) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '订单唯一标识',
`state` varchar(11) COLLATE utf8mb4_bin DEFAULT NULL COMMENT 'NEW 未支付订单,PAY已经支付订单,CANCEL超时取消订单',
`create_time` datetime DEFAULT NULL COMMENT '订单生成时间',
`pay_amount` decimal(16,2) DEFAULT NULL COMMENT '订单实际支付价格',
`nickname` varchar(64) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '昵称',
`user_id` bigint DEFAULT NULL COMMENT '用户id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
相关配置文件如下:
# 打印执行的数据库以及语句
spring.shardingsphere.props.sql.show=true
# 数据源 db0
spring.shardingsphere.datasource.names=ds0
# 第一个数据库
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://124.223.63.123:3306/shop_order_0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=xxxxxxxxxxxxxxxxxxxxxxxxxxxxx(替换成你自己的)
# 指定product_order表的数据分布情况,配置数据节点,行表达式标识符使用 ${...} 或 $->{...},但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $->{...}
spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds0.product_order_$->{0..1}
# 指定product_order表的分片策略,分片策略包括【分片键和分片算法】
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.algorithm-expression=product_order_$->{user_id % 2}
配置解析:采用行表达式分片策略,根据user_id进行分片。
编写测试用例:
@SpringBootTest(classes = ShardingJdbcDemoApplication.class)
@Slf4j
@RunWith(SpringRunner.class)
class ShardingJdbcDemoApplicationTests {
@Autowired
private ProductOrderMapper productOrderMapper;
@Test
public void testSaveProductOrder(){
for(int i=0;i<10;i++){
ProductOrderDO productOrder = new ProductOrderDO();
productOrder.setCreateTime(new Date());
productOrder.setNickname("向往"+i);
productOrder.setOutTradeNo(UUID.randomUUID().toString().substring(0,32));
productOrder.setPayAmount(100.00);
productOrder.setState("PAY");
productOrder.setUserId(Long.valueOf(i+""));
productOrderMapper.insert(productOrder);
}
}
}
运行结果如下:
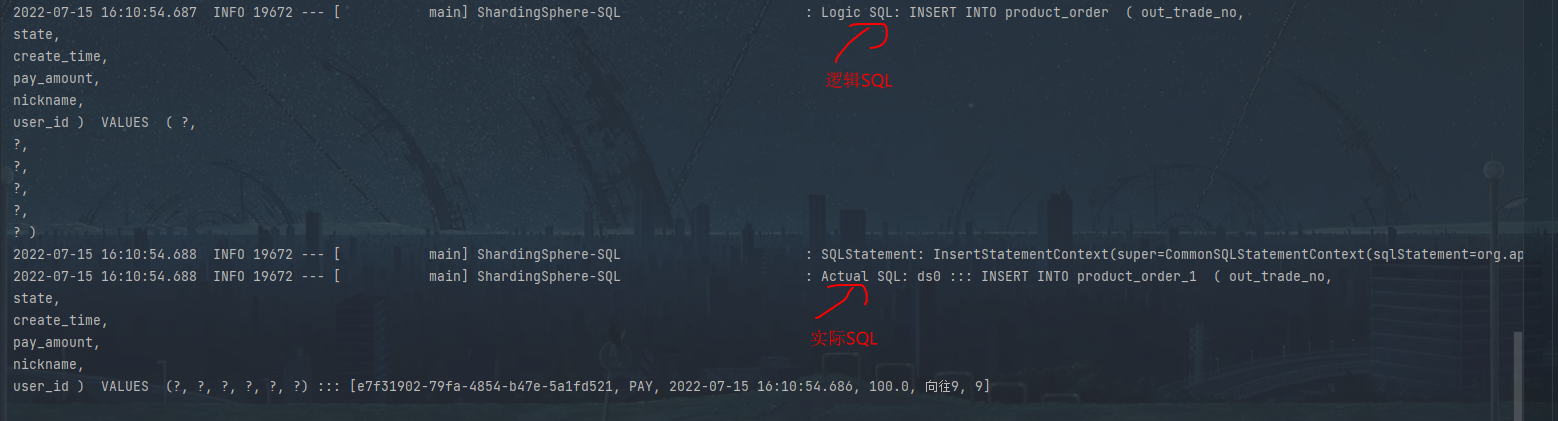
user_id为0,2,4,6,8分配到表product_order_0,user_id为1,3,5,7,9分配到表product_order_1。
Hint分片策略HintShardingStrategy
新建shop_order_1数据库,添加表product_order_0和product_order_1`,生成Sql参考上面的:
自定义分库策略:
public class CustomDBHintShardingAlgorithm implements HintShardingAlgorithm<Long> {
/**
* @param dataSourceNames 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param hintShardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),hit策略此处为空 ""
* <p>
* value 【之前】都是 从 SQL 中解析出的分片健的值,用于取模判断
* HintShardingAlgorithm不再从SQL 解析中获取值,而是直接通过
* hintManager.addTableShardingValue("product_order", 1)参数进行指定
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> dataSourceNames, HintShardingValue<Long> hintShardingValue) {
Collection<String> result = new ArrayList<>();
for (String tableName : dataSourceNames) {
for (Long shardingValue : hintShardingValue.getValues()) {
if (tableName.endsWith(String.valueOf(shardingValue % dataSourceNames.size()))) {
result.add(tableName);
}
}
}
return result;
}
}
自定义分表策略:
public class CustomTableHintShardingAlgorithm implements HintShardingAlgorithm<Long> {
/**
* @param dataSourceNames 数据源集合
* 在分库时值为所有分片库的集合 databaseNames
* 分表时为对应分片库中所有分片表的集合 tablesNames
* @param hintShardingValue 分片属性,包括
* logicTableName 为逻辑表,
* columnName 分片健(字段),hit策略此处为空 ""
* <p>
* value 【之前】都是 从 SQL 中解析出的分片健的值,用于取模判断
* HintShardingAlgorithm不再从SQL 解析中获取值,而是直接通过
* hintManager.addTableShardingValue("product_order", 1)参数进行指定
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> dataSourceNames, HintShardingValue<Long> hintShardingValue) {
Collection<String> result = new ArrayList<>();
for (String tableName : dataSourceNames) {
for (Long shardingValue : hintShardingValue.getValues()) {
if (tableName.endsWith(String.valueOf(shardingValue % dataSourceNames.size()))) {
result.add(tableName);
}
}
}
return result;
}
}
配置文件:
spring.application.name=sharding-Jdbc-demo
server.port=8080
# 打印执行的数据库以及语句
spring.shardingsphere.props.sql.show=true
# 数据源 db0
spring.shardingsphere.datasource.names=ds0,ds1
# 第一个数据库
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://124.223.63.123:3306/shop_order_0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=xxx
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://124.223.63.123:3306/shop_order_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=xxx
# 指定product_order表的数据分布情况,配置数据节点,行表达式标识符使用 ${...} 或 $->{...},但前者与 Spring 本身的文件占位符冲突,所以在 Spring 环境中建议使用 $->{...}
#spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds0.product_order_$->{0..1}
spring.shardingsphere.sharding.tables.product_order.actual-data-nodes=ds$->{0..1}.product_order_$->{0..1}
# 指定product_order表的分片策略,分片策略包括【分片键和分片算法】
#spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.tables.product_order.table-strategy.inline.algorithm-expression=product_order_$->{user_id % 2}
## HINT分片算法
spring.shardingsphere.sharding.tables.product_order.database-strategy.hint.algorithmClassName=com.example.shardingjdbcdemo.service.CustomDBHintShardingAlgorithm
spring.shardingsphere.sharding.tables.product_order.table-strategy.hint.algorithmClassName=com.example.shardingjdbcdemo.service.CustomTableHintShardingAlgorithm
标准分片策略StandardShardingStrategy-精准分片
只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分⽚算法,PreciseShardingAlgorithm 精准分⽚ 是必选的,⽤于处理
=和IN的分⽚,RangeShardingAlgorithm 范围分配 是可选的,⽤于处理BETWEEN AND分⽚,如果不配置RangeShardingAlgorithm,如果SQL中⽤了
BETWEEN AND语法,则将按照全库路由处理,性能下降。
复合分片策略ComplexShardingStrategy
⽀持多分片键,多分⽚键之间的关系复杂,由开发者⾃⼰实现,提供最⼤的灵活度。