Mysql引擎及索引浅析
[TOC]
概述
索引是一种特殊的文件,包含着对数据表里面所有记录的引用指针,索引的目的在于提高查询效率,将原始的随机全表扫描变成快速顺序锁定数据。
常见索引
常见索引分类:
- 普通索引:基本索引,没有使用闲置,一般命名为idx_xxx
- 唯一索引: 引列的值必须唯一,允许有空值
- 组合索引: 多个数据列组成的索引,遵守最左匹配原则
索引底层数据结构
常见的检索方案有二叉树查找、hash索引、B-TREE、B+TREE。二叉树单层节点存储的数据量较少,需到多层遍历多层才能定位到数据;hash等值检索快,但范围查询效率很低;B-TREE的结构如下图所示:
,如图如果需要查询2-85的数据,需要对各个节点都进行遍历。
哈希索引(hash index)基于哈希表实现,只有精确匹配索引所有列的查询才有效进。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码,哈希码是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。在MySQL中,只有Memory引擎显式支持哈希索引。这也是Memory引擎表的默认索引类型,Memory引擎同时也支持B-Tree索引。值得一提的是,Memory引擎是支持非唯一哈希索引的,这在数据库世界里面是比较与众不同的。如果多个列的哈希值相同,索引会以链表的方式存放多个记录指针到同一个哈希条目中。
InnoDB引擎
InnoDB存储结构如下:
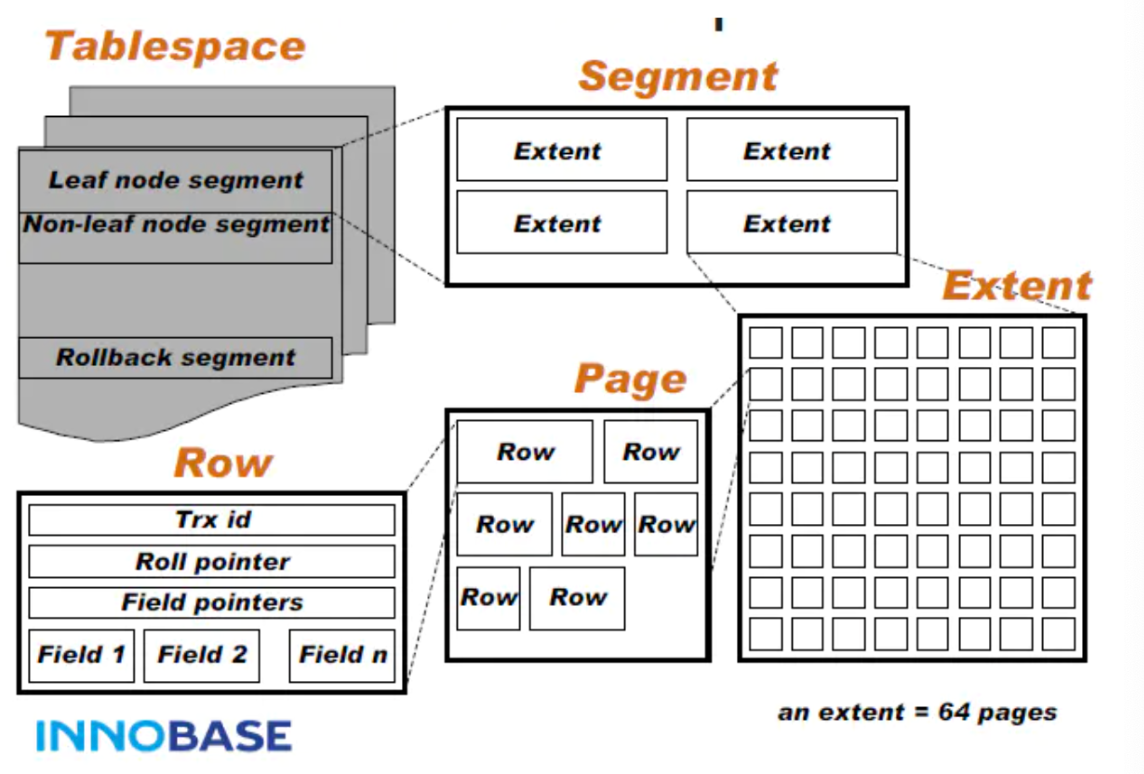
- InnoDB以表空间Tablespace(idb文件)结构进行组织,每个Tablespace 包含多个Segment段,每个段(分为2种段:叶子节点Segment&非叶子节点Segment), 一个Segment段包含多个Extent,一个Extent占用1M空间包含64个Page(每个Page 16k),InnoDB B+Tree 一个逻辑节点就分配一个物理Page,一个节点一次IO操作。,一个Page里包含很多有序数据Row行数据,Row行数据中包含Filed属性数据等信息。
myIsam引擎
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址,MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复,结构如下图所示。
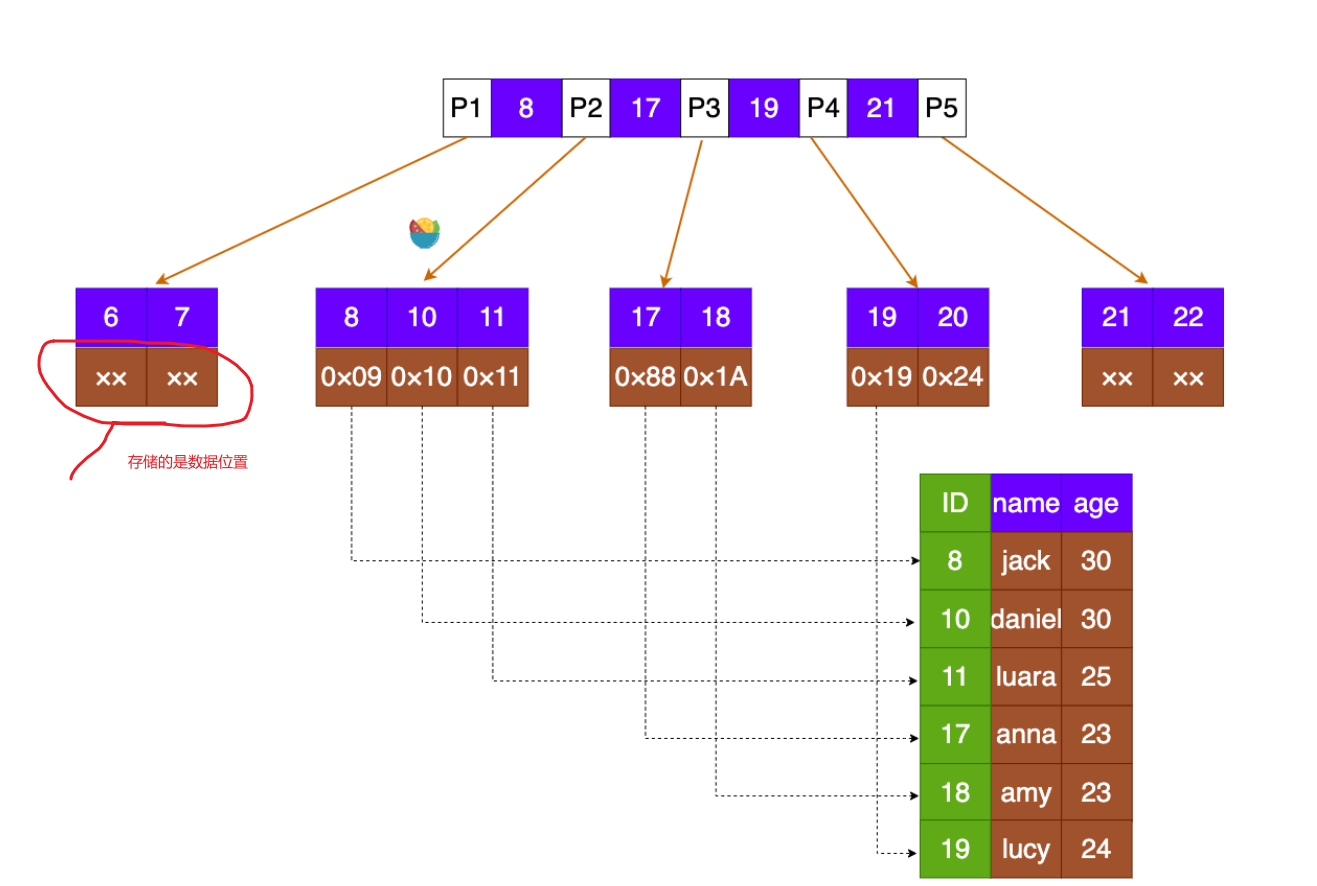
补充:
聚簇索引:将数据存储和索引放到一起,都是按照一定的顺序组织,找到索引也找到了数据,数据的物理存储和索引顺序是一致的(InnoDB)
非聚簇索引:叶子结点只存储数据地址,不存储数据(MyISAM)
InnoDB和Mylsam区别
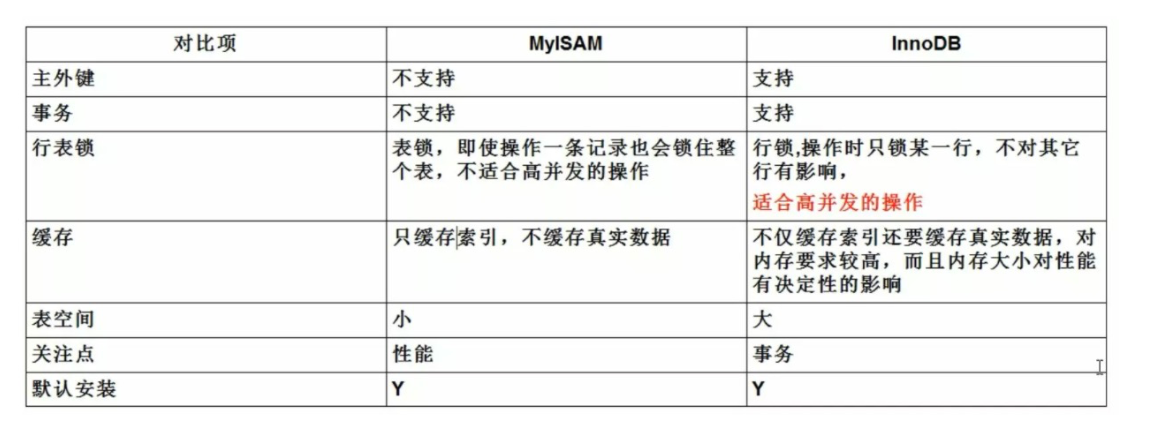
- InnoDB是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。MyISAM是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的
- InnoDB支持事务,MyISAM不支持
- InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快
- Innodb不支持全文索引,而MyISAM支持全文索引,查询效率上MyISAM要高
实际业务场景选择:
- 是否要支持事务,如果要请选择innodb,如果不需要可以考虑MyISAM;
- 如果表中绝大多数都只是读查询,可以考虑MyISAM,如果既有读写也挺频繁,请使用InnoDB